
Realizar un proyecto de ciencia de datos con Python
Introducción
Este capítulo ofrece la oportunidad de poner en práctica, en un proyecto real, gran parte de los conceptos y técnicas abordados en este libro. Los notebooks de este proyecto están disponibles en la siguiente dirección: https://github.com/eric2mangel/UsedCarPricePredictor
Para que la demostración sea más fluida, solo retomaremos las partes más importantes. Sin embargo, todos los experimentos estarán disponibles en los notebooks.
El tema: determinar el precio de los vehículos de ocasión
1. Los datos
Los datos provienen del sitio web de Kaggle y están disponibles en esta dirección: https://www.kaggle.com/datasets/wspirat/germany-used-cars-dataset-2023
La licencia es «CC0: Dominio Público», lo que significa que los datos se colocan en el dominio público y se pueden utilizar libremente. Asegúrese de verificar y respetar siempre los términos de uso de un conjunto de datos.
Nuestro conjunto de datos es una colección de ofertas de venta de coches de ocasión de uno de los sitios web alemanes más grandes en del sector: AutoScout24. Ofrece una amplia gama de modelos y versiones de vehículos. En total, hay 251 079 vehículos.
2. Las etapas del proyecto
Pondremos en práctica un enfoque clásico para el procesamiento y modelado de datos, teniendo cuidado de separar la parte de feature engineering y la parte de modelado. Este enfoque es relevante porque nos permite centrarnos en cada parte de forma independiente. Además, a la hora de modelar, podemos partir de los datos transformados, evitando tener que recargar todo desde el principio.
a. El notebook de EDA
El notebook de EDA cubrirá la adquisición, limpieza, exploración, análisis y finalización de datos. Nuestro conjunto de datos solo presenta 15 variables, pero algunas como la marca, el modelo...
Modelado en la práctica
1. Notebook 1: EDA
a. Adquisición de datos y comprobaciones iniciales
Antes de comenzar, es necesario descargar los datos cuyo enlace se proporcionó al comienzo del capítulo y guardarlos en una carpeta de nuestra elección.
Procedamos, pues, con la adquisición:
import pandas as pd
import numpy as np
pd.set_option("display.max_columns", 999)
raw = pd.read_csv(r"YOUR_PATH\data.csv",low_memory=False,sep=",")
brut.head() 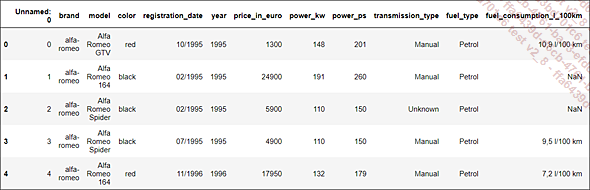
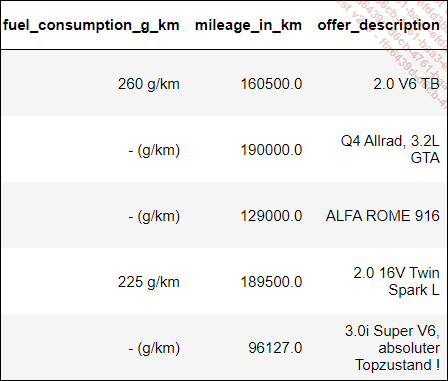
El archivo, presentado en dos partes por restricciones de legibilidad, incluye 15 variables y 251 079 observaciones.
La primera variable es un índice incremental que se puede eliminar inmediatamente:
raw = raw.drop(["Unnamed: 0"],axis=1) A continuación, cambiaremos el nombre de la variable offer_description a version para mayor comodidad:
raw.rename(columns={'offer_description': 'version'},
inplace=True) Ahora podemos ver las características globales del conjunto de datos:
raw.info() 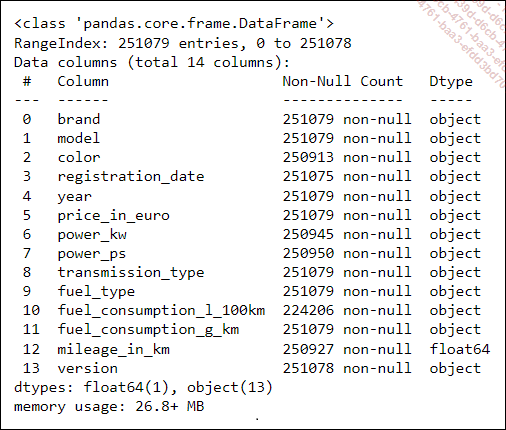
La calidad de cumplimentación es globalmente muy buena, con una tasa de finalización general promedio del 99,22 %. La variable fuel_comsumption_l_100km tiene la tasa de relleno más baja, con un 89,3 %.
Al desplazarse por los datos, se observa que algunos precios han sido reemplazados por el nombre de la empresa. Dado que nuestro modelo se centrará en la predicción de precios, en este momento podemos eliminar todas las observaciones que no tengan un precio numérico. Recuperaremos los valores numéricos en una nueva variable price y cuantificaremos el número de observaciones no numéricas:
raw['price'] = pd.to_numeric(raw["price_in_euro"],
errors='coerce')
non_num_price = raw[raw['price'].isna() &
raw["price_in_euro"].notna()]
non_num_price.shape
# Output: (199,15) Disponemos...
Conclusión
En conjunto, al igual que en la simulación anterior, aparecen las mismas variables destacadas. Aunque el rendimiento ha mejorado, estos experimentos muestran que cada intento de optimización requiere lidiar con restricciones, particularmente en términos de potencia de cómputo. Aquí, sería imposible considerar un GridSearchCV porque nuestras máquinas simplemente no son lo bastante potentes como para llevar a cabo estas búsquedas exhaustivas en un período de tiempo razonable. El equilibrio entre el rendimiento y la viabilidad sigue siendo, la mayoría de las veces, el principal reto.