
Introducción
Datos en todas partes
Todo es dato. La más mínima información almacenada en un medio digital puede ser recuperada y explotada. No importa la naturaleza del archivo: documento de texto, hoja de cálculo, imagen, logs o incluso un archivo de vídeo; todo se puede utilizar. Estos archivos no se limitan a nuestros ordenadores, los encontramos en todas partes: en nuestro teléfono, en nuestro coche, en la Web o en simples sensores. Y estos son solo datos preexistentes. Esta inmensa biblioteca de conocimientos se puede enriquecer aún más con cualquier cosa que todavía no esté registrada: fotos en papel, libros o cosas que actualmente solo están en nuestra cabeza, como una historia personal o una receta de cocina.
No hay escasez de datos. A veces incluso podemos sentir que hay demasiados. Por este motivo se acuñó el término «infobesidad» para describir este fenómeno.
Sin embargo, esta sobreabundancia abre las puertas a infinitas posibilidades en términos de nuevos conocimientos y a un campo lleno de diferentes opciones que se derivan de ellos. Nos encontramos en una situación en la que lo que debería preocuparnos no es tanto la materia prima, que son los datos, sino nuestra capacidad para evaluar su calidad, seleccionarlos, adquirirlos y transformarlos para extraer información útil. Cualquier proceso de ciencia de datos comienza con los datos y nosotros nos vamos a centrar en empezar a estudiar su origen.
1. Fuente de los datos
Como resultado, los datos son omnipresentes, están en constante evolución y adoptan diversas formas. Lo único que tiene que hacer es actualizarlos y el término «data mining» ilustra claramente este proceso de extracción de información oculta y valiosa por analogía con la extracción de gemas.
Las fuentes de información no son equivalentes en términos de calidad. Podemos definir tres familias principales de procedencia de los datos.
a. La Web
De manera original, la Web es una gigantesca reserva anárquica de datos. Con la conciencia de su importancia, hemos visto el desarrollo del open data. Pero ¿qué es el open data en términos concretos? Podríamos definirlo como el deseo de organizar los datos acumulados para facilitar su acceso y su uso. Este movimiento ha crecido mucho y ahora podemos tener acceso rápido y fácil a todo tipo de información. Todas las organizaciones -en primer lugar, los Estados- han puesto sus datos a disposición del público en general de forma gratuita en formatos accesibles y reutilizables. Cualquier persona puede utilizar estos datos para proyectos de todo tipo, ya sean comerciales o no. Aquí hay una lista no exhaustiva de enlaces con los que familiarizarse:
-
Datos del gobierno sobre múltiples temas:
-
Datos de ONG:
-
Datos locales:
Aparte de los datos abiertos, miles de millones de datos aún están esperando a que se descubran sus secretos. Pero tendremos que hacerlo nosotros mismos, asegurándonos de respetar las condiciones de recuperación y uso de la información de los sitios web. A esto se le llama «web scraping», del que aprenderemos conceptos básicos un poco más adelante.
b. Datos privados
Las empresas también poseen una gran cantidad de datos que formarán la segunda fuente principal. Cualquier información, ya sea financiera, comercial o técnica, puede ser analizada. Sin embargo, esto se debe lograr en el marco del Reglamento General de Protección de Datos (RGPD), destinado a proteger la privacidad de las personas y garantizar la seguridad de los datos personales en Europa.
El RGPD es europeo, pero tiene equivalentes en todo el mundo, como PIPEDA en Canadá, LGPD en Brasil o APPI en Japón. Todos están destinados a proteger los datos personales, aunque existen variaciones específicas de cada jurisdicción.
He aquí un diagrama que presenta las seis reglas principales del RGPD que se deben respetar:
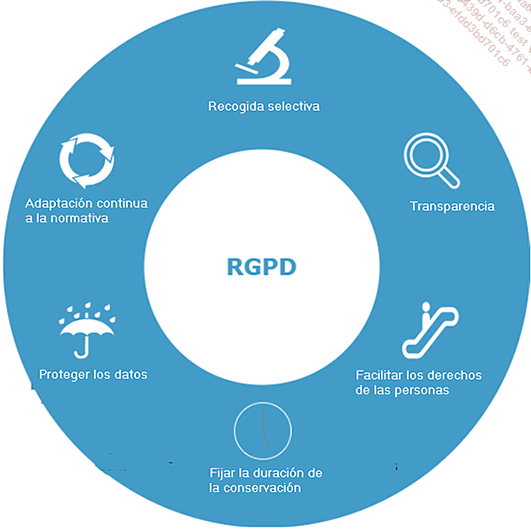
En cuanto al almacenamiento de los datos, también es importante asegurarse de que se alojan en una zona sujeta a la aplicación del RGPD.
c. Creemos nuestros propios datos
Por último, si toda la información disponible, pública o privada, no satisface nuestras necesidades...
Ciencia de datos
La ciencia de datos es un campo multidisciplinario que moviliza una variedad de técnicas estadísticas, matemáticas y de ciencias de la computación.
Su objetivo se puede resumir en dos pasos principales:
-
Feature engineering: recopilación, limpieza, exploración y análisis de datos.
-
Modelado: implantación, optimización y mantenimiento de sistemas de toma de decisiones.
El siguiente diagrama servirá para dar una visión general y facilitará la navegación en este libro:
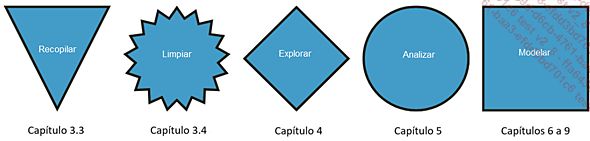
1. Feature engineering
La feature engineering, literalmente ingeniería de características, es el primer paso importante en la intervención de un científico de datos. Abarca todas las operaciones que preceden al modelado de los sistemas de decisión, como la adquisición de datos, su limpieza, exploración, análisis, selección y preparación. Podríamos definirlo como la fase de preparación previa a la acción. Este es un paso crucial porque la calidad de nuestro modelo futuro dependerá en gran medida del cuidado que se tenga en esta fase. Tratemos de detallar, en orden, estas diferentes etapas a partir de un ejemplo ficticio.
a. Recogida de datos
Un fabricante de helados nos encargó que le ayudáramos a entender y mejorar sus ventas. Él nos da los detalles. Empezaremos por comprobar si los datos están en un formato procesable. De hecho, dependiendo de los análisis deseados, a menudo será necesario modificar la presentación de los datos para satisfacer nuestras necesidades. Además, estos datos suelen estar compuestos por varias tablas cuyas claves primarias será necesario identificar con el fin de vincularlas.
Recuerde que una clave primaria es una columna o un conjunto de columnas que tienen valores únicos para cada fila y que identifican de forma única cada registro de una tabla.
Supongamos que tenemos los detalles de las ventas y el sabor del helado; seguramente tendremos que vincular este sabor a su precio unitario, presente en otra tabla. En este caso, el sabor será la clave primaria.
En casos más complejos, puede ser necesario el uso de un diccionario de variables. Este documento servirá como guía detallando el significado, tipo de variables o cualquier otra información que ayude a comprender los datos. No debe avanzar al siguiente paso de limpieza hasta que se haya familiarizado completamente con todos los datos que se utilizarán.
b. Limpieza
Los datos a menudo necesitan un paso de limpieza antes de estar listos para su uso. Siempre requieren reformateos adicionales o correcciones. Un caso clásico para nuestro ejemplo sería mostrar el precio con el símbolo €, que indica al consumidor la moneda utilizada, pero nos impedirá hacer cálculos porque la variable no se puede considerar numérica. Estos cambios son ligeros y rápidos de corregir; pero otros, como los valores que faltan, serán más difíciles de resolver. En este caso, la primera cuestión es si la ausencia de una respuesta es posible o aceptable. Si no es así, podemos completar haciendo lo que se llama una imputación.
Esta operación consiste en sustituir los valores que faltan por la media de la variable, su mediana o su valor modal para las variables numéricas, y simplemente el valor modal para las variables categóricas. También hay técnicas más sofisticadas que desarrollaremos en la parte práctica. En los casos en que la imputación resulte demasiado arriesgada, podemos considerar no tener en cuenta los datos que estén demasiado incompletos. Esta disyuntiva es un verdadero desafío y nos obliga a cuestionar las implicaciones de cada opción.
Una vez realizada la limpieza, podemos empezar a manipular los datos para evaluarlos.
c. Exploración
No sabemos a priori cuáles son las características de nuestro conjunto de datos. Empecemos por descubrir sus dimensiones, la calidad del relleno y, posteriormente, manipulando y visualizando, sabremos cuántos helados se venden al día en promedio, si hay sabores que no se venden, cuál fue el mejor y el peor día, si las ventas tienden a aumentar o no, etc. Entonces nos daremos cuenta de la realidad sobre el terreno.
La visualización se convertirá en un valioso aliado al resaltar inmediatamente los aspectos específicos de los datos estudiados. He aquí un ejemplo para ilustrar este fenómeno:
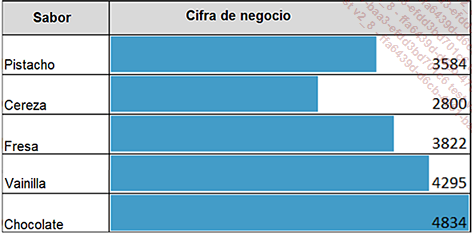
Las barras azules hablan por sí solas y percibimos enseguida la facturación generada por cada sabor. Esta familiarización con el campo de estudio generará observaciones y preguntas que luego verificaremos en la siguiente parte.
d. Análisis
El análisis sigue directamente a nuestra exploración. Primero utilizaremos pruebas estadísticas para determinar la generalización de las observaciones comprobadas en el paso anterior. Esta fase se denomina inferencia estadística y consiste en validar mediante métodos de generalización si lo que observamos durante la exploración de nuestra muestra se podría generalizar a toda la población.
Concretamente, si estudiamos las ventas de helados entre semana y el fin de semana, la diferencia tendrá que llegar a un cierto nivel en función de la muestra para que podamos decir que hay una diferencia significativa y así considerar relevante este tipo de división. Por debajo de este umbral, la diferencia podría provenir del efecto de ordenación y no se debería tener en cuenta. El número de personas juega un papel crucial aquí: cuantas más observaciones tengamos, menores serán los márgenes de incertidumbre en torno a los valores constatados y más significativa podría llegar a ser una diferencia, por pequeña que resulte.
A continuación, estudiaremos las variables de una en una, de dos en dos y luego de forma global para perfeccionar completamente nuestro conocimiento de los datos y de su funcionamiento. Estos estudios se denominan...
Python
Python fue creado en febrero de 1991 por Guido van Russom, un desarrollador holandés. Este lenguaje, de mediana edad en comparación con sus pares, ha pasado desde entonces por muchas versiones hasta convertirse gradualmente en el más popular del mundo. Aquí presentaremos los orígenes de su éxito.
1. Fortalezas naturales de Python
Python es conocido por su simplicidad y flexibilidad, lo que lo convierte en una buena opción para cualquier principiante en programación. Los usuarios más experimentados también apreciarán su versatilidad, potencia y capacidad para fomentar el trabajo en equipo, colaborar y mantener proyectos. Con tales ventajas, muchas comunidades se han formado a lo largo del tiempo y han contribuido activamente a su difusión en los círculos profesionales, fortaleciendo aún más su popularidad. Poco a poco, se convirtió en el lenguaje más popular y ha podido evolucionar con el tiempo. Sin duda, el secreto de su longevidad se debe a las diversas y potentes librerías establecidas por su comunidad.
2. Librerías especializadas
La versatilidad de Python no ha dejado de evolucionar. En cada campo, han surgido módulos dedicados que se han convertido en referencias con el tiempo.
Así, en el ámbito de los datos, Pandas se ha consolidado porque facilita enormemente todo el ciclo de acciones que se pueden encontrar en un ETL (Extract Transform Load) clásico:
-
Pandas gestiona una amplia variedad de fuentes de datos diferentes.
-
Ofrece una amplia gama de funciones para realizar todo tipo de procesamiento de datos.
-
A continuación, los datos se pueden exportar en múltiples formatos.
Y estas posibilidades no se detienen ahí. También tenemos la posibilidad de producir una gama completa...