
Aprendizaje no supervisado
Introducción
El aprendizaje no supervisado es un método de Machine Learning que tiene como objetivo descubrir patrones, grupos o estructuras en datos sin etiquetar. A diferencia del aprendizaje supervisado, donde la presencia de datos etiquetados permite evaluar un algoritmo mediante un score de rendimiento, el enfoque no supervisado es más sutil y requiere un análisis exhaustivo de los resultados obtenidos. Estos resultados, entregados sin instrucciones de uso, pueden revelar información oculta en los datos, como agrupaciones naturales o características destacadas.
En este capítulo, pondremos en práctica la reducción dimensional y luego el clustering. También descubriremos, para cada uno de ellos, cómo evaluarlos y cuáles son los diferentes algoritmos disponibles.
La reducción dimensional
El análisis de componentes principales (ACP) es un algoritmo fundamental en la ciencia de datos que permite reducir la dimensionalidad de los datos al mismo tiempo que se conserva su varianza tanto como sea posible. Esta técnica se puede utilizar en dos puntos específicos de un proyecto de ciencia de datos:
-
Al final de la feature engineering: para comprender y visualizar las relaciones multidimensionales entre variables.
-
A veces en el momento del modelado: ya sea para suavizar los datos o para permitir que ciertos algoritmos funcionen de manera más eficiente cuando los requisitos de memoria son demasiado grandes.
Por lo tanto, estudiaremos cómo ponerlo en práctica en estos dos casos.
1. El ACP en la práctica para analizar
El Análisis de Componentes Principales (ACP) es una herramienta esencial en el análisis multidimensional. Ayuda a revelar las relaciones complejas y ocultas entre las variables, al mismo tiempo que identifica su influencia en un conjunto de datos. Además, el ACP aísla las observaciones influyentes, proporcionando una visión más precisa de los datos.
Esta información es accesible a través de tres gráficos que aprenderemos a construir sucesivamente sobre el conjunto de datos del Titanic, que presenta información diversa y destacará las fortalezas del ACP.
a. Preparación de los datos
La preparación de los datos es necesaria antes de la implementación de un ACP. Para que el ACP funcione correctamente, es preciso:
-
Transformar las variables categóricas en binarias si se han seleccionado algunas. El uso de funciones como el get_dummies de Pandas permite realizar estas transformaciones en las variables a las que se dirige la opción columns.
-
Definir una estrategia para eliminar los valores ausentes: imputamos por la mediana para simplificar, aunque faltan el 20 % de las edades (177), lo que requeriría un análisis más profundo.
-
Estandarizar datos: se recomienda el uso de StandardScaler, pero se puede usar RobustScaler (si hay outliers) o MinMaxScaler (para dar el mismo peso a todas las variables), según el caso.
Para ilustrar nuestro ejemplo, vamos a realizar un pequeño estudio sociológico de los pasajeros del Titanic. Para ello, utilizaremos las variables age, survived (sobrevive o no), alone (viajaba solo o no)...
Clustering
1. La práctica del clustering con K-means
K-means es el más famoso de los algoritmos de clustering. Su objetivo es agrupar las observaciones cercanas en clústeres. Es apreciado por su simplicidad de explicación y configuración. Una de sus características clave es la posibilidad de establecer el número de clústeres deseados, lo que no siempre es el caso con sus competidores.
Sin embargo, determinar el número óptimo de clústeres no es evidente por sí mismo y constituye un desafío. Existen varios métodos y pruebas, como el método del codo (elbow method) o el coeficiente de silueta, para ayudarnos a encontrar la partición ideal de los datos.
Comencemos, sin más preámbulos, la práctica de clustering sobre el juego de los pingüinos, que se presta bien para una demostración de este tipo de análisis.
a. Adquisición y preparación de los datos
Importamos el juego de datos de los pingüinos y hacemos una limpieza rápida de datos eliminando las observaciones con valores ausentes:
import seaborn as sns
import pandas as pd
# Cargar los datos de los pingüinos
df = sns.load_dataset("penguins")
# Eliminar las líneas con valores ausentes
df = df.dropna()
display(df.head()) 
Construiremos nuestro clustering solo con variables numéricas para no hacer este ejemplo demasiado complejo, pero, en otros casos, se recomienda el uso de variables categóricas si es necesario.
En este caso, las cuatro variables, que corresponden a la longitud del pico, su profundidad, la longitud de la aleta y la masa corporal, parecen ser suficientes para realizar agrupaciones. Después de asegurarnos de que todos tienen una distribución atípica, producimos una matriz de correlación de Spearman para comprobar que no hay una correlación demasiado fuerte:
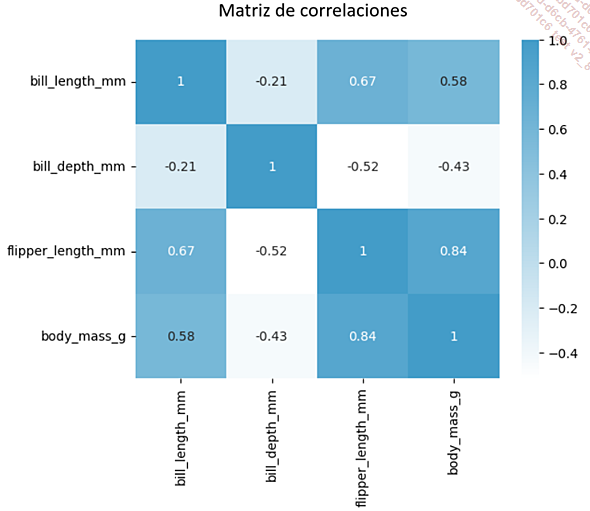
La longitud de la aleta y la masa corporal están fuertemente correlacionadas (0,84), pero no son idénticas y tienen naturalezas muy diferentes. Por lo tanto, se conservarán todas las variables.
Podemos proceder a la selección final de las características que se van a normalizar, con el fin de garantizar una escala homogénea para todos.
# Seleccionar las características...