
Conceptos básicos y entornos de Python
Los notebooks
Este capítulo no pretende hacer una introducción a Python, sino más bien preparar un entorno de trabajo funcional; se debe considerar como una aclaración antes de continuar. Quienes ya estén familiarizados con los notebooks y sean usuarios habituales de Python pueden abordar directamente el siguiente capítulo. Para todos los demás, comenzaremos presentando un medio de programación alternativo que vamos a utilizar: el notebook.
1. Principio del notebook
En comparación con un programa clásico que contiene código, el notebook ofrece un enfoque revolucionario de la programación al llevar la interactividad al marco austero habitual. Así es como se ve:
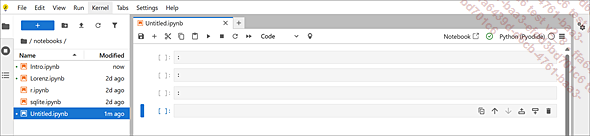
a. Funcionamiento por celdas
El notebook funciona por celdas. Esta es la primera característica, ya que cada celda se puede lanzar independientemente de las demás. Este enfoque es muy relevante en términos pedagógicos porque permitirá al alumno lanzar específicamente la(s) celda(s) deseada(s) y facilitar la manipulación. Además, cada celda puede ser de dos naturalezas diferentes y contener código o texto.
b. Posibilidad de anotar el código
El texto aportará esta segunda capa de interactividad al permitir al usuario anotar lo que está haciendo, arrastrar comentarios o simplemente añadir capítulos y subcapítulos. De este modo, pasamos...
Comandos básicos
Aquí, revisaremos algunos conceptos fundamentales de Python que son de vital importancia para el uso de Python en la ciencia de datos.
1. Adquisición de datos
Antes de iniciar cualquier análisis de datos, es fundamental adquirirlos. Estos son los pasos que debe seguir para completar esta primera etapa.
a. Definición de carpeta de trabajo
Empecemos por definir en qué archivo vamos a trabajar. Esta pequeña rutina nos facilitará la tarea al evitar dar la ruta completa cada vez que queramos acceder a un archivo. La definición de la carpeta de trabajo pasa por el módulo os. Lo configuramos usando el comando os.chdir y confirmamos que ha funcionado correctamente con el comando os.getcwd().
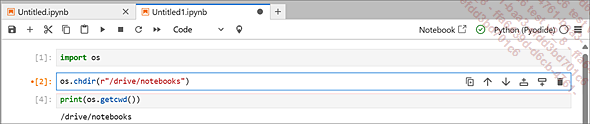
Ahora que la carpeta está definida, el programa apunta a ella y ya no es necesario indicar su ruta completa.
Todos los archivos de muestra se han almacenado en la subcarpeta DATA, por lo que la ruta siempre comenzará con DATA/nombre_archivo.tipo.archivo.
b. Acceso a los datos
El acceso a los datos se puede realizar de una manera bastante sencilla. Estos son algunos ejemplos para leer los formatos de datos más comunes, empezando por CSV, que es un formato de texto con un separador. Es fundamental conocer el separador para que el archivo se lea correctamente. De forma predeterminada, se usa la coma para los archivos de EE. UU., mientras que, para los archivos españoles, se usa el punto y coma. Para facilitar estas operaciones, usaremos la librería Pandas, que veremos en detalle en el capítulo Preparar los datos con Pandas y NumPy.
Leer archivos CSV
import pandas as pd
my_comma_csv = pd.read_csv("DATA/csv_ingles.csv")
my_semicolon_csv = pd.read_csv("DATA/csv_es.csv",sep=";") Leer archivos de Excel
La lectura de archivos de Excel requiere instalar previamente el módulo xlrd. A continuación, se explica cómo instalarlo (se debe hacer desde el símbolo del sistema):
pip install xlrd Ahora podremos leer los dos tipos de extensión de archivo de Excel gracias al comando read_excel de pandas:
fic_xls =
pd.read_excel("DATA/File_xls.xls",sheet_name="nombre_pestaña") fic_xlsx =
pd.read_excel("DATA/File_xlsx.xlsx",sheet_name="nombre_pestaña") Leer archivos JSON
El formato JSON, abreviatura de JavaScript...
Uso avanzado
La práctica de la ciencia de datos requiere el dominio de algunas de las características más avanzadas de Python, que nos centraremos en definir.
La importación de las diferentes librerías necesarias para la realización de nuestro programa es lo primero en nuestro código. Es importante empezar por ver cómo manejarlas.
1. Gestión de las librerías
Las librerías son conjuntos de funciones de Python que facilitan el manejo de problemas complejos. Permiten escribir código de manera mucho más fácil y generar programas que no podríamos implementar sin ellas. Antes de ver cómo funcionan, hay que señalar que una librería evoluciona con el tiempo, que a menudo recurre a otras librerías que también evolucionan y no es raro encontrar problemas de compatibilidad entre ellas. Por este motivo, saber cómo entender y mantener este ecosistema es un paso sencillo, aunque obligatorio, para poder llevar a cabo nuestra tarea.
Usaremos los términos «librería» y «módulo» para referirnos indistintamente a las librerías.
a. Instalación
La instalación de un módulo es una operación muy común. Lo único que tiene que hacer es abrir un símbolo del sistema, independientemente de la plataforma, y escribir (tenga cuidado de poner pip en minúsculas):
pip install nombre_modulo En esta ilustración, recurrimos a Windows PowerShell en Windows:

Conviene precisar aquí que, en Windows, el comando se debe ejecutar en la subcarpeta Scripts de la carpeta del programa Python. Para asegurarnos, comprobaremos que existe un archivo llamado pip.exe.
b. Actualización
A medida que las librerías evolucionan, es posible que se deban actualizar. Se puede conocer la versión de una librería de dos maneras:
-
O mostrando la versión de todas las librerías presentes:
pip freeze -
O bien solicitando los detalles de una librería en particular con el siguiente comando:
pip show <nombre_modulo> Una vez conocida la versión, podemos proceder a actualizar el paquete:
pip install --upgrade <nombre_modulo> c. Eliminación
Una librería se puede eliminar si ya no se utiliza:
pip uninstall <nombre_modulo> Sin embargo, asegúrese de que no sea necesaria para la ejecución...