
En el corazón de la máquina
Introducción al procesador central del ordenador
Los procesadores de una unidad central de proceso (CPU, de Central Processing Unit) funcionan al ritmo de un circuito de «reloj», que actualmente tiene una frecuencia variable según un equilibrio entre eficiencia y consumo de energía.
Por ejemplo, la CPU de la marca Intel denominada Core i9-12900KF tiene una frecuencia base de 3,2 GHz y suele alcanzar los 4,55 o incluso 5,2 GHz.
Un gigahercio (símbolo: GHz) corresponde a mil millones de ciclos por segundo, lo que es considerable si se tiene en cuenta que la corriente alterna en España es de 50 Hz y que el oído humano no puede distinguir sonidos agudos por encima de 20 000 Hz (ni graves con una frecuencia inferior a 16 Hz).
Desde la década de los 2000, se han tenido que poner en marcha nuevas estrategias para seguir duplicando, cada dos años, el número de componentes en una misma superficie de silicio, a la vez que se duplicaba la potencia del chip en cuestión (lo que a menudo se conoce como «ley de Moore», aunque esta denominación ha sido objeto de mucho debate).
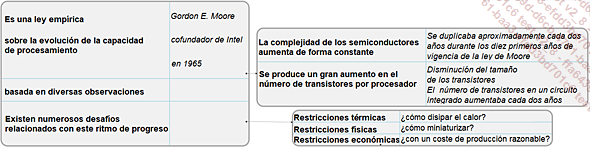
La ley de Moore en pocas palabras
Ya no podemos contentarnos con miniaturizar los componentes y aumentar la frecuencia. De hecho, estamos llegando a límites físicos y el calentamiento es demasiado grande. Añadir sistemas de refrigeración funciona, pero da lugar a máquinas...
Funcionamiento del procesador y del ensamblador
1. La unidad central de proceso (CPU) desde cerca
En uno o varios ciclos, cada thread ejecuta una única instrucción antes de pasar a la siguiente. Una instrucción puede ser una suma (ADD), la carga o descarga de un valor (LOAD), un salto a una instrucción que no es contigua (JMP) o una comparación entre dos valores (CMP) que condiciona un posible salto a otra instrucción. Los lenguajes informáticos capaces de describir (codificar) una secuencia de estas instrucciones se denominan ensambladores. Todos los demás dialectos informáticos son superposiciones que permiten implementar un código similar al producido por un ensamblador.
La memoria propia de un procesador es muy limitada y consiste en unos pocos espacios de memoria de acceso rápido conocidos como registros (normalmente de 16, 32 o 64 bits) y la dirección de la siguiente instrucción que se va a ejecutar (denominada contador ordinal, puntero de instrucción, program counter, instruction address register o instruction pointer, a menudo simbolizada por un $ o por las siglas PC o EIP).
Cuando se activa la instrucción señalada por el contador ordinal, se inicia un ciclo completo (conocido como ciclo de instrucción o fetch-decode-execute cycle). La etapa fetch proporciona acceso a los detalles de la instrucción, que luego se decodifican y ejecutan durante un determinado número de pulsos de reloj. Podemos encontrar una lectura o escritura (I/O para Input/Output) soportada por la interrupción que gestiona un periférico como un teclado o una pantalla, la invocación de la unidad aritmética lógica (ALU) para realizar cálculos binarios con números enteros o la invocación de la FPU (Floating-Point Unit), que gestiona cálculos con números reales. Se llaman así porque el punto (.) de un número decimal no está siempre en el mismo lugar (para comprobarlo, compare 100.1 y 3.1416).
Se dispone de un pequeño número de registros generales. Los cuatro registros de 32 bits de una arquitectura x86/32 bits se denominan:
-
EAX para «Acumulador»; también se utiliza a menudo para definir entradas/salidas,
-
EBX para «Base de direccionamiento indirecto»,
-
ECX para «Contador de bucle»,
-
EDX para «Datos»....
Alrededor de la CPU
1. Inicio de la secuencia de arranque de un ordenador
Ya hemos identificado el reloj y podemos imaginar que, para que el procesador se ponga en marcha, necesita tener acceso a ciertas instrucciones de arranque. A menudo, estas instrucciones se encuentran en un chip CMOS (Complementary Metal-Oxide Semiconductor) con una memoria «casi» no volátil NVRAM (Non-Volatile Random-Access Memory), que mantiene estas instrucciones accesibles porque está respaldada por una batería (normalmente una pila de botón de 3 V). De hecho, con frecuencia, el circuito del reloj y diversos elementos que deben conservarse, como la fecha y la hora, también se almacenan en un chip CMOS de este tipo.
Al arrancar, las primeras instrucciones que ejecuta el procesador suelen almacenarse en este tipo de componente. En un PC convencional, se denomina BIOS (Basic Input/Output System). En muchos casos, este programa puede ser parametrizado por el usuario a través de una interfaz hombre-máquina relativamente rudimentaria que los usuarios están acostumbrados a llamar «la BIOS». Estas interfaces difieren de un proveedor de placas base a otro; algunas permiten ajustes sofisticados de la máquina, otras no. Por ejemplo, se puede elegir el orden en el que se revisan los discos en los que se desea buscar el sistema operativo (que todavía no se ha iniciado en esta fase), establecer las características de los discos físicos de la máquina, elegir las frecuencias de funcionamiento de la CPU, configurar una contraseña de acceso a la BIOS, elegir la frecuencia de funcionamiento de los módulos de memoria, establecer los umbrales de temperatura que activarán la refrigeración de la CPU o de la carcasa, etc.
En los PC modernos, la BIOS está equipada con numerosas capacidades encapsuladas en un firmware que se comporta como un minisistema operativo, llamado UEFI (Unified Extensible Firmware Interface). Por razones de compatibilidad o para que estas máquinas puedan funcionar con distintos sistemas operativos, a menudo es posible elegir si se utilizan o no las funciones UEFI. En la interfaz, la elección de la BIOS «habitual» se denomina a veces legacy.
De hecho, el término legacy es peyorativo: significa «heredado» e introduce la idea de que el sistema o la máquina en cuestión...
Los ordenadores actuales calculan en binario
Nosotros calculamos en base 10 y las máquinas lo hacen en base 2.
Los valores binarios (en base 2) que maneja el ordenador se nos presentan a menudo en hexadecimal (base 16) o en octal.
Por ejemplo, en nuestro código ensamblador, 0x80 designaba el identificador hexadecimal (reconocible por el prefijo 0x utilizado en los lenguajes C y ensamblador) del código del núcleo de Linux.
Por lo tanto, verá códigos de error del sistema expresados en hexadecimal con este prefijo, ya que el ensamblador y C se utilizan ampliamente para las capas más bajas de código.
El octal se usa cada vez menos, pero en algunos idiomas o en códigos informáticos antiguos las convenciones utilizadas pueden inducir a error. Por ejemplo, los números se prefijaban con un «0» para indicar que eran octales, por lo que la expresión 0100 no significaba 100 en decimal, sino 64 en octal. A veces, se utilizaba «\» como prefijo octal, lo que habría dado \100 en nuestro ejemplo.
1. Algunas reflexiones sobre la representación decimal de los números enteros (base 10)
En base 10, un número entero natural (positivo o cero) se representa mediante una serie de símbolos, tomados de entre 10 (de 0 a 9), que representan los valores cero y los 9 números positivos siguientes. A modo de recordatorio, he aquí algunas potencias de 10, vistas de forma «algorítmica»:
-
10 elevado a 0 = 1
-
10 elevado a 1 = 1 * 10 = 10
-
10 elevado a 2 = 10 * 10 = 100
-
10 elevado a 3 = 100 * 10 = 1000
-
10 elevado a 4 = 1000 * 10 = 10000...
Por ejemplo, el número entero 593 (en nuestra base 10 habitual) representa la siguiente suma:
5 x 100 + 9 x 10 +3 x1
En otras palabras:
5.102+ 9.101+ 3.100
2. Introducción al cálculo hexadecimal (base 16)
La representación hexadecimal es utilizada a diario por técnicos e ingenieros que trabajan en redes informáticas y sus aplicaciones. No sería razonable excluirla de sus conocimientos básicos.
La base 16 tiene una serie de ventajas:
-
Proporciona representaciones más compactas que la base 10, ya que es mayor que 10 y, por tanto, sus potencias de 16 crecen más rápido.
-
Es múltiplo de 2, lo que, como veremos más adelante, facilita su transcripción en binario.
Los 16 símbolos utilizados...
Codificación de caracteres
Cuando se utiliza un editor de texto, la línea de comandos, una base de datos convencional o una hoja de cálculo, se manipulan principalmente expresiones en forma de texto.
Estas expresiones incluyen caracteres alfabéticos, representaciones de los diez dígitos (tenga en cuenta que no son los valores lo que está manipulando, sino el carácter, es decir, una referencia al «dibujo» que los representa), caracteres más raros -como una barra vertical (|)- y, por último, caracteres especiales, invisibles si no se solicita verlos, que tienen la particularidad de afectar al aspecto del texto cuando se visualiza en la pantalla o cuando se edita en papel (como el carácter invisible «salto de línea» para partir línea o el carácter «tabulador»).
Los programas que manipulan estos datos textuales los interpretan y almacenan según sus propios objetivos. Un editor de texto le permite ver los caracteres de su idioma e interpreta ciertos caracteres especiales, como el salto de línea o el tabulador, en lugar de mostrárselos (a menos que se lo pida explícitamente). Una hoja de cálculo hace lo mismo, excepto en determinadas celdas que usted ha definido como numéricas, en cuyo caso interpreta la cadena de caracteres que representan números (así como los caracteres más, menos, coma o punto) para reconstituir un valor numérico, que luego se manipula y guarda como tal.
Cuando usted abre un archivo con extensión .csv en un editor de texto sencillo como Vim, Nano o Notepad++, podrá comprobar que ese archivo está formado por líneas con estructuras similares que incluyen caracteres, incluso para valores numéricos. La prueba de ello es que puede eliminar un solo carácter de una expresión que representa un valor numérico; de lo contrario solo tendría la opción de eliminar toda la cadena o no eliminar nada. Si le pide a su editor que le muestre los caracteres especiales, le indicará dónde termina la línea.
En Windows, los finales de línea están formados por dos caracteres (retorno de carro, CR, y salto de línea, LF), mientras que en Linux solo se utiliza un carácter (LF). Cuando intercambie archivos entre dos sistemas, tiene que comprobar que la herramienta...
Sistemas de archivos
Los datos se almacenan (o «serializan») en distintos soportes, normalmente en discos duros. Para recuperar estos datos, es necesario disponer de una representación fiable y normalizada de los distintos agregados de datos: los archivos. Como estos se actualizan o se destruyen con regularidad, ha sido necesario poner en marcha distintas estrategias para dividir eficazmente estos datos en pequeñas partes. Esto se consigue particionándolos y gestionando directorios que los indexan, lo que permite memorizar la disposición de todas las partes constituyentes de los distintos archivos. Esta voluntad de organización eficaz y óptima se concreta en el concepto de «sistema de archivos».
Una observación preliminar sobre el arranque de un PC: existe un registro especial, llamado por ejemplo MBR, el Master Boot Record del disco, que se utiliza para cargar la partición del disco y determinar el sector de arranque de la máquina. Este nos permite invocar el sistema de archivos de la máquina y acceder a nuestros archivos.
Los siguientes sistemas de archivos son muy comunes (no hay que confundir sistema de archivos con formato de archivo; este último representa la organización lógica interna del archivo):
-
FAT32: 2 TB como máximo, MS/DOS y Windows, lento para archivos grandes, compatible con muchos otros SO y distribuciones Linux.
-
NTFS: más...
Tarjeta gráfica GPU, CUDA e IA
A diferencia de los conceptos anteriores, ahora vamos a analizar un elemento de configuración mucho más cercano al usuario final o a su estación de trabajo, así como a los nuevos hábitos de procesamiento de datos popularizados por ChatGPT: las tarjetas gráficas, es decir, las GPU.
Las GPU actuales son capaces de procesar grandes cantidades de datos en paralelo, lo que las hace especialmente adecuadas para tareas de alta carga computacional, como la inteligencia artificial (IA), la simulación científica y el renderizado de vídeo. Las GPU también se utilizan en los campos de la realidad virtual y aumentada, donde se requiere un alto rendimiento gráfico para crear experiencias inmersivas.
Las GPU potentes se utilizan en IA; en particular, a través de frameworks como TensorFlow y PyTorch, por varias razones:
-
Su capacidad de cálculo paralelo. Las GPU cuentan con miles de núcleos de procesamiento paralelo.
-
Su capacidad para acelerar las operaciones matriciales (de hecho, tensoriales), sobre todo al manipular los tensores (grandes matrices multidimensionales) que describen las capas de neuronas artificiales.
-
Su capacidad de procesamiento de datos masivos. La IA suele implicar el procesamiento de grandes cantidades de datos, por lo que aprovechamos los grandes buses de memoria de estas tarjetas.
El estándar de facto relativamente hegemónico...
Redes y comunicaciones de aplicaciones
1. Introducción a las redes locales
En la vida cotidiana, nuestras máquinas suelen estar conectadas a una LAN. Una LAN (Local Area Network) es una red local que conecta dispositivos, como ordenadores, impresoras y servidores, dentro de un área geográfica limitada, como un edificio, una oficina o una casa.
El objetivo de una red local es permitir la comunicación y el uso compartido de recursos entre los dispositivos conectados.
Las principales características de una red local son las siguientes:
-
Área geográfica limitada: las redes locales cubren un área relativamente pequeña, como un solo edificio o un grupo de edificios cercanos.
-
Conexión de alta velocidad: las redes locales suelen utilizar conexiones de alta velocidad, como Ethernet, para facilitar la transferencia rápida de datos entre dispositivos.
-
Recursos compartidos: los dispositivos de una red local pueden compartir recursos como impresoras, servidores y dispositivos de almacenamiento. Esto permite una colaboración y un uso eficientes de los recursos dentro de la red.
-
Control local: las redes locales suelen ser privadas y controladas por la organización o el individuo que las ha creado. Esto permite al administrador de la red gestionarla y protegerla según sus necesidades específicas.
Las redes de área local se utilizan habitualmente en hogares, pequeñas empresas, centros educativos y otros entornos, donde una red localizada es suficiente para satisfacer las necesidades de comunicación e intercambio de recursos de los usuarios.
Las redes locales pueden adoptar distintas topologías, es decir, los dispositivos están conectados según distintos patrones de relación.

¿Cómo se distribuyen las máquinas en una red?
Para encaminar los datos de un emisor a uno o varios destinatarios a través de la red, a menudo se establece un sistema de enrutamiento de red más o menos sofisticado que selecciona las rutas más adecuadas.
He aquí algunos tipos comunes de enrutamiento:
-
Unicast: encaminamiento de datos a un único destino específico;
-
Difusión: envío de datos a todos los destinatarios de la red;
-
Multidifusión: envío de datos a un grupo específico de destinatarios;
-
Anycast: envío de datos a uno de entre varios destinatarios...