
Las herramientas
Descripción general
Las herramientas Pump de Datos, Exportación, Import y SQL*Loader son herramientas muy potentes que tienen muchas funcionalidades; se podría dedicar un libro entero a ellas.
Por lo tanto, el objetivo de este capítulo es presentar los principios generales del funcionamiento de estas diferentes herramientas y dar algunos consejos sobre su utilización, ilustrados con algunos ejemplos clásicos de uso. Para profundizar en este tema puede consultar la documentación Oracle® Database Utilities.
Oracle ofrece tres herramientas que permiten administrar los datos contenidos en una base de datos:
-
Data Pump Export: permite exportar en un archivo binario propietario de Oracle todo o parte de los objetos (estructura y/o datos) de una base de datos;
-
Data Pump Import: permite importar en una base de datos todo o parte de los objetos (estructura y/o datos) inicialmente exportados mediante la herramienta Data Pump Export;
-
SQL*Loader: permite cargar en las tablas de una base de datos los datos almacenados en archivos ASCII.
Las herramientas Pump de Datos aparecieron en la versión 10. En las versiones anteriores, existen dos herramientas equivalentes llamadas simplemente Export e Import. Estas herramientas existen todavía por razonas de compatibilidad hacia atrás, pero las herramientas Pump de Datos ofrecen más funcionalidades (consulte las observaciones más adelante).
Para utilizar estas herramientas...
Pump de Datos
1. Presentación
a. Arquitectura
Pump de Datos es una herramienta de servidor que se puede utilizar para mover datos y/o metadatos (definiciones) entre las bases de datos Oracle.
Data Pump tiene tres elementos:
-
un paquete PL/SQL DBMS_DATAPUMP;
-
un paquete PL/SQL DBMS_METADATA;
-
dos herramientas cliente por línea de comandos expdp (export) e impdp (importación).
Las herramientas clientes expdp e impdp sirven de interfaz con el paquete DBMS_DATAPUMP que es, en cierta medida, la API (Application Programming Interface) de Data Pump. Este paquete está completamente documentado, lo que permite utilizar directamente las funcionalidades Data Pump en un programa.
Las operaciones propiamente dichas de exportación e importación se realizan con el paquete DBMS_DATAPUMP y, por tanto, en el servidor Oracle. Esto incluye fundamentalmente la lectura y/o escritura de los archivos: los archivos generados durante una exportación se escriben en el servidor y los archivos cargados durante una importación se leen en el servidor. El acceso a los archivos en el servidor se realiza gracias a los objetos DIRECTORY; un objeto DIRECTORY es un alias de un repositorio del sistema operativo. Estos objetos DIRECTORY se deben crear por el DBA (consulte la sección El objeto DIRECTORY).
Cuando se crea un trabajo Pump de Datos, Oracle crea diferentes estructuras para gestionar la operación, entre las que podemos encontrar:
-
una tabla llamada "maestra" en el esquema del usuario que crea el trabajo (esta tabla tiene el mismo nombre que el trabajo);
-
un proceso de control maestro (llamado Dan) que controla la ejecución del trabajo.
La tabla "maestra" contiene diversa información acerca del trabajo, que se utiliza fundamentalmente para volver a arrancar el trabajo. La tabla "maestra" se elimina normalmente cuando el trabajo termina o cuando el trabajo se eliminar mediante el comando KILL_JOB (como veremos más adelante); en caso necesario, esta tabla se puede eliminar directamente a mano con ayuda de una sentencia SQL DROP TABLE.
b. Los modos de exportación e importación
Pump de Datos ofrece cinco niveles (modos) para las operaciones de exportación e importación:
-
Completa: totalidad de la base de datos;
-
Esquema: uno o varios esquemas;
-
Tabla: una o varias tablas;
-
Tablespace: todas las tablas almacenadas en uno o varios tablespaces;
-
Tablespace...
SQL*Loader
1. Descripción general
a. Presentación
SQL*Loader es una herramienta muy potente que permite cargar datos:
-
desde uno o varios archivos externos;
-
con registros de longitud fija o variable (con delimitadores);
-
en una o varias tablas;
-
aplicando operaciones, controles o filtros a los datos.
b. Funcionamiento general
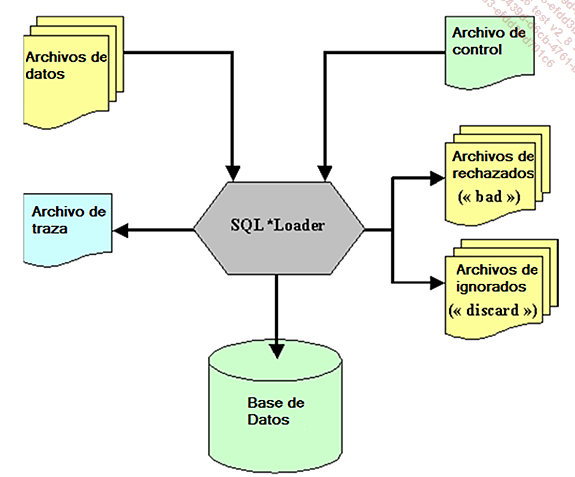
Como entrada, SQL*Loader recibe un archivo de control (nada que ver con el archivo de control de una base de datos), que controla la carga y uno o varios archivos de datos ASCII (no archivos de datos de una base de datos Oracle).
Como salida, SQL*Loader alimenta la base de datos Oracle y genera un archivo de traza (log), un archivo de rechazos (bad - datos rechazados) y un archivo de descartes (discard - datos descartados).
Para pequeños volúmenes, los datos se pueden incluir de manera directa en el archivo de control.
El archivo discard contiene los registros que se han descartado por SQL*Loader porque no respetan las condiciones especificadas en el archivo de control.
El archivo bad contiene los registros que se han sido ignorados por SQL*Loader (formato del registro no válido respecto a la descripción del archivo de control), o por Oracle (violación de una restricción de integridad, tipo de dato no válido, etc.).
Los registros rechazados o ignorados se escriben tal cual en los archivos bad y discard que tienen, por tanto, la misma estructura que los archivos de datos utilizados como entrada; después de la eventual corrección de los registros, los archivos bad y discard se pueden utilizar como archivos de entrada.
El archivo de traza da mucha información del resultado de la carga:
-
fecha;
-
nombre de los archivos utilizados;
-
argumentos utilizados;
-
tablas de destino y modo de alimentación;
-
condiciones eventuales de los registros;
-
número de registros cargados;
-
número de registros rechazados;
-
número de registros erróneos;
-
mensajes de error relativos a los erróneos.
c. Las rutas de carga
SQL*Loader puede realizar la carga siguiendo dos "caminos":
-
Camino convencional: los datos se cargan en memoria y se insertan en las tablas mediante sentencias SQL INSERT clásicas;
-
Camino directo: los datos se cargan en memoria y se formatean en los bloques, que se escriben de manera directa en la base de datos.
Con el camino convencional, se aplican todos los mecanismos clásicos (restricciones, triggers...
Extraer datos en un archivo de texto
1. En SQL
En SQL, es suficiente con escribir un script con la consulta SELECT deseada y dirigir la salida a un archivo (SPOOL). Adicionalmente, es conveniente ejecutar algunos comandos SQL*Plus para eliminar los objetos que no se desean visualizar (títulos de columnas, número de registros seleccionados, etc.).
Ejemplo de script SQL: exportación con registros de longitud fija
-- configuración del entorno SQL*Plus
-- sin echo para las consultas
SET ECHO OFF
-- ocultar los títulos de columnas
SET HEADING OFF
-- ocultar que se muestre el número de registros en el resultado
SET FEEDBACK OFF
-- dimensionar la longitud del registro a 1000 caracteres
-- (sin utilidad aquí, pero sirve como ejemplo)
SET LINESIZE 1000
-- eliminar el salto de línea en cada cambio de página
SET NEWPAGE NONE
-- eliminación de los espacios al final del registro
SET TRIMSPOOL ON
-- sin visualización por pantalla (más rápida)
SET TERMOUT OFF
-- dirigir la salida a un archivo .txt
SPOOL miembro.txt
-- ejecutar una consulta SELECT que concatene las diferentes columnas
-- y utilizar, si es necesario, la función SQL RPAD para añadir
-- espacios a las columnas...Utilizar Oracle SQL Developer
EM Express no ofrece ninguna página para realizar exportaciones, importaciones o carga de datos. Para ello es posible utilizar Oracle SQL Developer.
1. Pump de Datos
a. Introducción
En el panel DBA, la carpeta Pump de Datos da acceso a las diferentes funcionalidades que permiten utilizar Pump de datos:
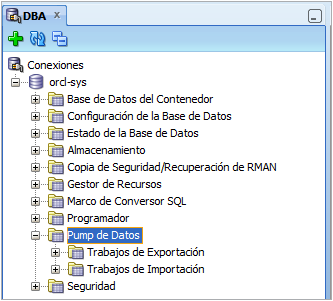
Las dos subcarpetas Trabajos de Exportación y Trabajos de Importación permiten ver los trabajos de exportación e importación actualmente en ejecución.
En el menú contextual que se muestra cuando hace clic con el botón derecho en la carpeta Pump de Datos tiene la posibilidad de arrancar un asistente que le permitirá realizar una exportación o importación con Pump de Datos:

Los dos asistentes prohíben utilizar una conexión SYS para realizar una exportación o una importación con ayuda de Pump de Datos. Por tanto, tendrá que crear otra conexión (SYSTEM, por ejemplo).
Estos dos asistentes explotan directamente el paquete DBMS_DATAPUMP para ejecutar los trabajos de exportación e importación.
b. Asistente Export Pump de Datos
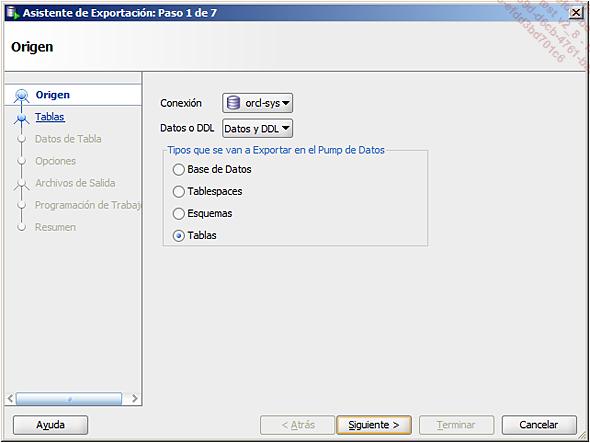
La primera etapa permite seleccionar la conexión que se va a utilizar, el contenido de la exportación y el tipo de exportación.
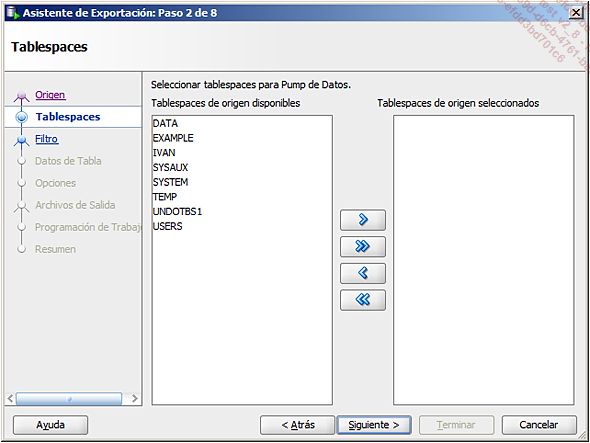
Las siguientes etapas dependen del tipo de exportación. Por ejemplo, en caso de una exportación a nivel de Tablespaces, que contiene datos y metadatos (DDL), el asistente le ofrece sucesivamente:
-
seleccionar uno o varios esquemas para exportar.
-
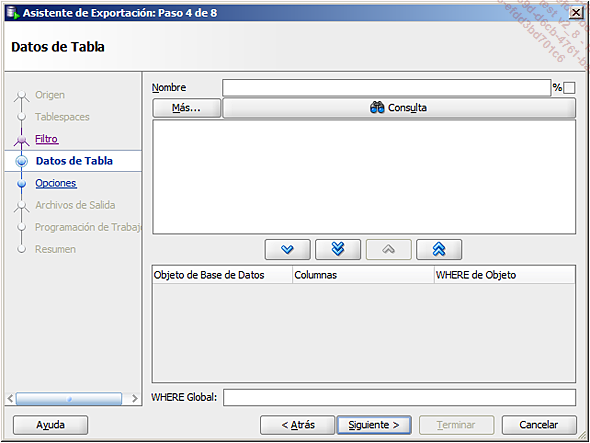
concretar los objetos que se deben incluir o excluir de la exportación:
-
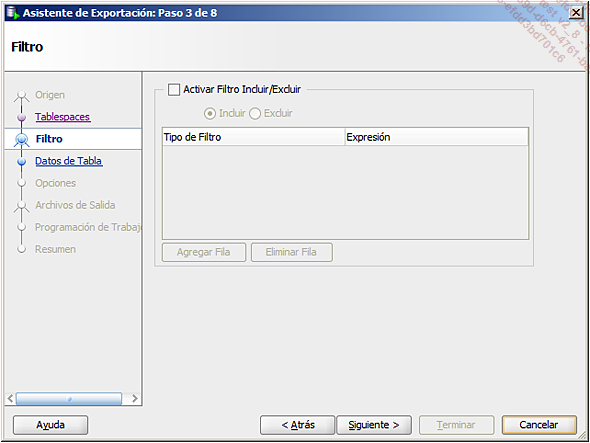
definir los filtros de los datos:
-
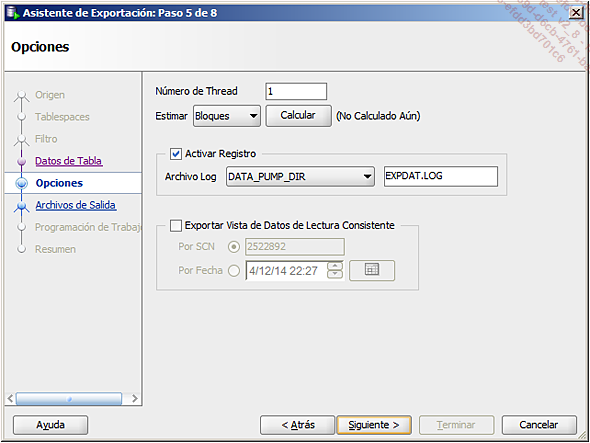
especificar las opciones de exportación (número de threads, archivo de traza, coherencia de la exportación, etc.):
-
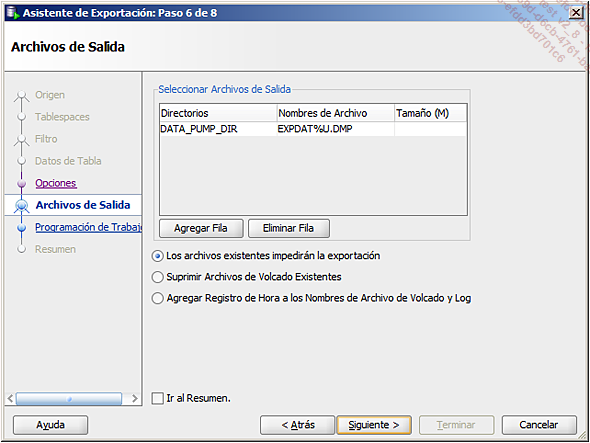
definir el nombre y la ubicación del archivo de exportación:
-
dar un nombre y programar el trabajo (inmediatamente, más tarde, opcionalmente repetido a intervalos regulares):
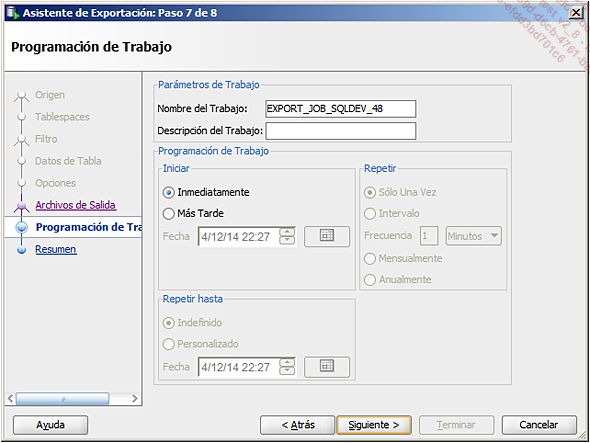
-
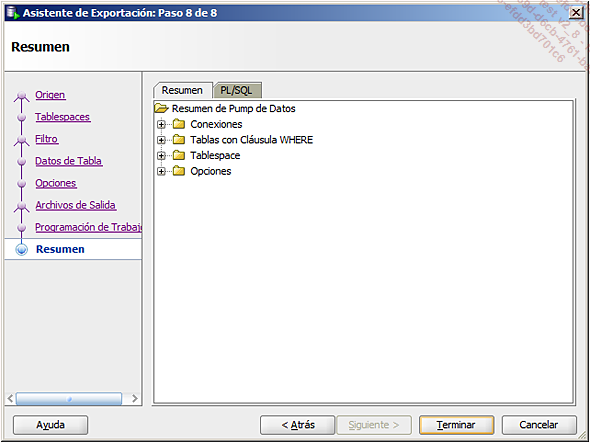
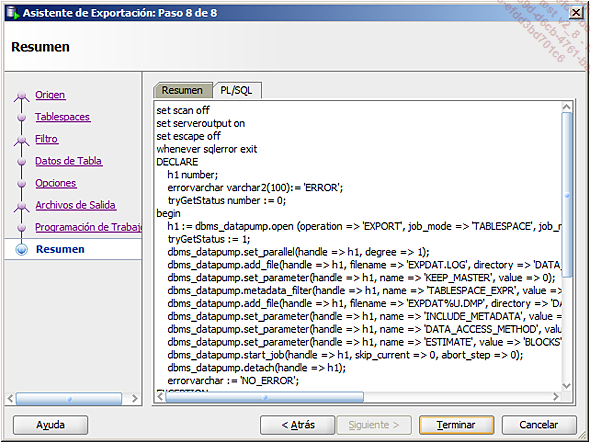
ver el trabajo en una pantalla de resumen:
c. Asistente Import Pump de Datos
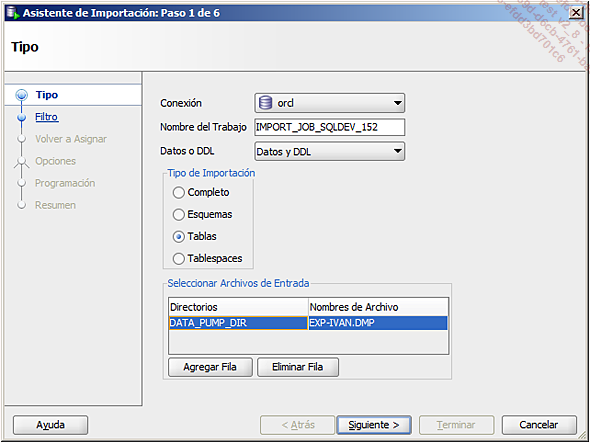
La primera etapa permite seleccionar la conexión que se va a utilizar, el contenido de la importación, el tipo de importación, así como que el nombre y la ubicación del archivo a importar.
Las etapas siguientes dependen del tipo de importación. Por ejemplo, en el caso de una importación a nivel de Esquemas que contiene...
