
La pila tecnológica en Python
Herramientas de la Data Science
Un buen artesano necesita buenas herramientas. Esto también es cierto en la Data Science (Ciencia de Datos) y el Machine Learning.
Existen tres categorías principales de herramientas:
-
Herramientas «integradas» que contienen todo lo necesario para un proyecto: cargar datos, analizarlos, crear modelos, evaluarlos, desplegarlos, crear informes, etc.
-
Herramientas «Auto ML» que simplifican el proceso para los inexpertos, automatizando al máximo las distintas fases.
-
Herramientas de «desarrollo» con las que se pueden hacer más cosas, siempre que se codifique todo; por ejemplo en Python.
1. Herramientas integradas
Hay muchas herramientas en la primera categoría, y cada una requiere una formación específica para sacarle el máximo partido. Además, cada una tiene sus puntos fuertes y débiles, por lo que es importante saber elegir el software adecuado para cada fin.
Entre ellas: Dataiku DSS, SAS, QlikView, Tableau, Power BI, Snowflake y otras. Algunas están muy orientadas a la estadística (SAS), otras a la visualización de datos (Tableau), pero todas cubren al menos parte del proceso. Se trata principalmente de aplicaciones que pueden descargarse y a las que se accede a través de una interfaz web.
Tenga en cuenta que la mayoría de este software es de pago. A menudo hay versiones gratuitas, pero tienen funciones...
Lenguaje Python
1. Presentación
Python es un lenguaje de programación cuya primera versión se publicó en 1991. Así que es un lenguaje maduro que los desarrolladores conocen desde hace mucho tiempo.
Tiene varias características:
-
Interpretado: significa que no hay que compilarlo antes de poder ejecutar el código. Por tanto, es fácil de depurar, pero esto lo hace menos eficiente en términos de tiempo de ejecución que los lenguajes compilados como C/C++. Sin embargo, como la mayoría de las bibliotecas de «bajo nivel» están codificadas en C, el código sigue siendo de alto rendimiento.
-
Multiplataforma: el código Python no depende de la plataforma en la que se ejecuta, por lo que tiene mucha portabilidad y es fácil de compartir. En concreto, es compatible con Windows, Unix, Mac OS, Android e iOS.
-
Multiparadigma: Python permite diferentes formas de programación y, por tanto, es adecuado para la mayoría de los desarrolladores. Se puede escribir:
-
En programación interactiva, la forma más antigua de programación
-
En la programación orientada a objetos, la forma de programación preferida por los desarrolladores de todos los lenguajes
-
Y en programación funcional, permitiendo evaluar funciones matemáticas y manipular listas de forma simplificada.
-
Legible: Python no contiene delimitadores de bloque, a diferencia...
Jupyter
1. Características de Jupyter
Jupyter es un programa que permite crear «cuadernos» (notebooks en inglés). Cada cuaderno es en realidad una página de cualquier tamaño, en la que las celdas están enlazadas entre sí.
Cada célula puede ser de distinto tipo:
-
Código que puede ejecutarse y cuyo resultado se mostrará inmediatamente debajo de la celda al ejecutarse.
-
Texto sin formato y mostrado tal cual.
-
Texto en Markdown, para maquetación de páginas e incluso fórmulas en LaTeX.
Markdown es un lenguaje de formato ligero creado en 2004 y utilizado en muchas aplicaciones informáticas. Por ejemplo, los títulos de nivel 1 empiezan por #, los de nivel 2 por ##, etc. El texto se escribe en cursiva y negrita rodeándolo de asteriscos: *itálica*, **negrita**.
LaTeX es un lenguaje de composición de documentos. Muy utilizado en círculos académicos, separa la escritura del texto de su maquetación. La maquetación se calcula al compilar el texto en bruto, respetando las restricciones tipográficas y el modelo deseado. El lenguaje LaTeX es muy apreciado por su capacidad para escribir fácilmente ecuaciones complejas.
He aquí un ejemplo de cómo se formatea y despliega un cuaderno:
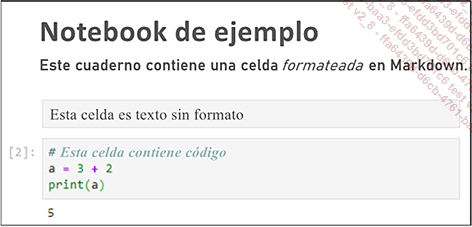
Cada cuaderno debe estar asociado a un núcleo. Se trata de un entorno que contiene el lenguaje de programación principal del notebook y los paquetes instalados. Esto permite ejecutar en paralelo diferentes versiones del mismo lenguaje.
Por tanto, es posible tener en el mismo Jupyter un núcleo en Python 3.6 y otro en Python 3.9, con módulos diferentes. De hecho, cada núcleo puede tener sus propias bibliotecas o versiones diferentes de ellas, lo que evita en parte posibles conflictos.
Jupyter admite actualmente más de cuarenta lenguajes, entre ellos Python, R, Julia, Scala, etc. También se integra con Spark, que puede gestionar grandes volúmenes de datos particionados en varios nodos.
El formato en el que se guardan los cuadernos es un archivo .ipynb, que en realidad es un archivo JSON que contiene toda la información necesaria: contenido de las celdas y retornos si se guardan. A continuación, este cuaderno puede exportarse en los principales formatos de intercambio, incluidos PDF, HTML, EPS, etc.
El código JSON para el cuaderno mostrado arriba...
Bibliotecas de Machine Learning
Python por sí solo no es ni rápido ni fácil de usar para la Data Science ni para el Machine Learning. Por lo tanto, es necesario utilizar bibliotecas para simplificar el código y hacerlo más eficiente. La mayoría de los frameworks (marco de trabajo) están en realidad codificados en C/C++.
La instalación de las bibliotecas es bastante sencilla y puede realizarse mediante un comando pip (https://pypi.org/project/pip/) o a través de Conda (https://docs.conda.io/en/latest/).
También se pueden compartimentar las bibliotecas instaladas por proyecto utilizando entornos virtuales, por ejemplo, virtualenv (https://virtualenv.pypa.io/en/latest/) o pipenv (https://github.com/pypa/pipenv).
La presentación de las principales bibliotecas va acompañada de extractos de código, pero en los siguientes capítulos se ofrecerán más detalles.
1. NumPy
La primera biblioteca ampliamente utilizada en Data Science data de 1995. Facilita la manipulación de matrices y la realización de operaciones con ellas. Disponible como código abierto, está codificada principalmente en C, lo que la hace muy rápida.
La mayoría de los algoritmos de Machine Learning realizan un gran número de cálculos matriciales, de ahí la necesidad de esta biblioteca.
El sitio web de NumPy (https://numpy.org/) proporciona acceso a las últimas versiones, tutoriales y documentación de la biblioteca.
La primera característica importante de NumPy es que incluye un nuevo tipo de datos: ndarray (N-Dimensional Array).
Estas tablas, que en realidad representan matrices de N dimensiones, no son dinámicas: el tamaño debe elegirse antes de utilizarlas y no se puede modificarse después. Además, deben ser homogéneas: solo pueden contener un tipo de datos. Sin embargo, como es posible definir nuevos tipos (mediante clases dedicadas), es fácil almacenar lo que se necesita en función del problema.
Hay varias formas de crear un ndarray. Aquí vamos a dar los valores que contiene directamente:
import numpy as np
A = np.array([[1, -2, 3], [-4, 5, 6], [-7, 8, -9]])
B = np.array([10, 2, -3]) Para averiguar el tamaño de un ndarray, basta con utilizar el atributo shape:
A.shape
>...Bibliotecas de Deep Learning
Existen muchas bibliotecas de Deep Learning en el mercado. Todas son de código abierto.
La mayoría de ellas ofrecen las mismas posibilidades. Dependiendo del hardware o la arquitectura elegidos, algunas pueden estar un poco más optimizadas que otras. Otro criterio de elección puede ser la comunidad que hay detrás de la biblioteca, para poder obtener soporte si se tiene alguna duda.
Las principales librerías son:
-
TensorFlow, creada por el equipo de Google Brain. Está especialmente optimizado para el entrenamiento distribuido en varias GPU.
-
PyTorch, creada por Meta. La biblioteca ofrece numerosos ejemplos y casos de uso. Además, los modelos pueden compilarse para optimizar aún más la fase de inferencia.
-
MXNet, de la Fundación Apache y respaldada por AWS y Microsoft (entre otros). Al igual que TensorFlow, está especialmente optimizada para la computación distribuida en varias CPU o GPU, y se integra muy fácilmente con los distintos proveedores de la nube. Además, esta biblioteca puede utilizarse en varios lenguajes, lo que facilita el uso de los modelos: Python, pero también C++, JavaScript, R, etc.
-
Microsoft Cognitive Toolkit (ex-CNTK), creado por Microsoft. Sin embargo, la biblioteca parece haber sido archivada por el momento.
-
Keras, legible, fácil de usar y, a menudo, la favorita de los Científicos de Datos. Sin...




