
Extraer sus datos de cualquier fuente
Presentación de la biblioteca pandas
pandas es una herramienta indispensable para el análisis de datos, que ofrece una versatilidad y potencia notables. El objetivo de esta introducción es presentar sus principales características, centrándonos en el elemento clave: el DataFrame. Comenzaremos adquiriendo y extrayendo datos en forma de DataFrames, para pasar a procesarlos en el siguiente capítulo.
Los DataFrames son estructuras de datos flexibles y bidimensionales muy utilizadas en Python para manipular y analizar información. Este tutorial explorará la naturaleza de los DataFrames, su organización y sus atributos fundamentales. Este enfoque le ayudará a entender cómo transformar datos en bruto en información utilizable para el análisis.
1. ¿Qué es un DataFrame?
Un DataFrame puede considerarse como una tabla de base de datos o una hoja de cálculo de Excel, donde los datos se organizan en filas y columnas. Es una de las estructuras de datos principales que proporciona la biblioteca pandas, diseñada para gestionar y manipular datos de forma eficiente.
2. Estructura de un DataFrame
Un DataFrame se compone de varios elementos:
-
Índice: representa la secuencia de enteros o etiquetas utilizadas para identificar unívocamente cada línea del DataFrame. Puede ser generado automáticamente por pandas o especificado de forma manual.
-
Columnas:...
Archivos planos u otros formatos estructurados
En esta parte del libro, veremos cómo extraer datos de distintos tipos de archivos, clasificándolos por dificultad creciente. Es muy fácil leer un archivo CSV, pero resulta un poco complicado cuando hay que procesar un PDF o una imagen (aunque esto es menos habitual).
1. CSV, TXT y TSV
El formato CSV (Comma-Separated Values) es uno de los formatos de archivo plano más utilizados para almacenar datos. Menos restrictivo que un archivo Excel, puede gestionar volúmenes considerables de datos, lo que lo convierte en el formato predilecto para conjuntos de datos compartidos en plataformas especializadas como Kaggle.
La biblioteca pandas proporciona un método read_csv() capaz de leer una amplia variedad de archivos CSV. Aunque su sintaxis básica es sencilla, el dominio de sus muchos argumentos permite optimizar la lectura de datos en función de las necesidades específicas de cada proyecto.
En esta sección nos centraremos en los argumentos más utilizados. Con unos cincuenta disponibles, no sería eficaz memorizarlos todos. No obstante, la documentación oficial sigue siendo un recurso valioso para necesidades más concretas. Para facilitar la depuración, también veremos los mensajes de error más comunes y sus soluciones.
La siguiente tabla muestra los principales argumentos del método read_csv(). A continuación, exploraremos su uso práctico a través de algunos ejemplos concretos, ilustrando cómo estos parámetros pueden ajustarse para adaptarse a diferentes escenarios de lectura de datos.
|
Argumento |
Tipo |
Definición |
|
sep |
str |
indica el separador que debe utilizarse |
|
encoding |
str |
especifica la codificación del archivo CSV |
|
skiprows |
int |
no enlaza las n primeras líneas |
|
skipfooter |
int |
no enlaza las n últimas líneas |
|
usecols |
list |
selecciona solo las columnas que deben cargarse |
|
index_col |
int |
especifica la columna de índice |
|
header |
int |
indica la fila que contiene las etiquetas de las columnas |
|
dtype |
dict |
especifica el tipo de cada columna |
El método read_csv() devuelve un DataFrame. Este es el caso de uso más común:
import pandas as pd
CSV_PATH = './data/raw/source.csv'
df = pd.read_csv(CSV_PATH,
sep=','...Bases de datos relacionales
1. ¿Qué es una base de datos relacional?
Una base de datos relacional es una base de datos más general que se utiliza para una amplia variedad de aplicaciones. Las bases de datos relacionales utilizan una estructura denominada «modelo relacional», en la que los datos se almacenan en tablas (relaciones) definidas por columnas (atributos) y filas (tuplas). El objetivo principal de una base de datos relacional es el procesamiento de transacciones en línea (Online Transaction Processing, OLTP), que implica las operaciones diarias de una organización, como la entrada de pedidos, las transacciones financieras y la gestión de clientes.
Estas son las diferencias entre una base de datos relacional y un almacén de datos:
-
Diseñada para transacciones: las bases de datos relacionales suelen estar optimizadas para operaciones de escritura, lo que las hace ideales para sistemas transaccionales en los que los datos se insertan, actualizan o eliminan con frecuencia.
-
Estructura normalizada: en las bases de datos relacionales, las tablas suelen estar normalizadas, lo que significa que los datos se organizan para reducir la redundancia y mejorar su integridad.
-
Operaciones en tiempo real: las bases de datos relacionales se utilizan para gestionar datos operativos en tiempo real que cambian regularmente.
-
Control de concurrencia: como las bases de datos relacionales se utilizan para las operaciones cotidianas, están diseñadas para dar soporte a muchos usuarios simultáneamente.
2. ¿Cuáles son las bases de datos más comunes?
Esta sección y la siguiente presuponen una comprensión básica de los conceptos de base de datos relacional y del lenguaje SQL.
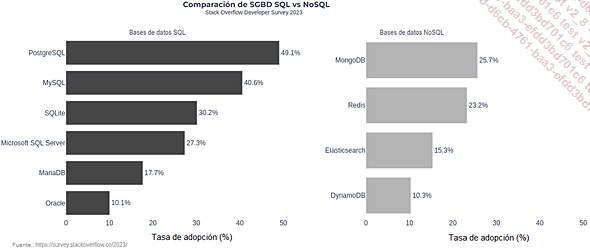
Según la última encuesta de Stack Overflow sobre las tecnologías más populares entre los profesionales, las 10 principales bases de datos incluyen tanto sistemas SQL como NoSQL. Para esta sección sobre bases de datos relacionales, nos centraremos en las tres más utilizadas de cada categoría.
Hay dos formas principales de conectarse a una base de datos en Python:
-
utilizar una biblioteca específica de la base de datos;
-
utilizar una biblioteca compatible con varios tipos de bases de datos.
Tomemos el ejemplo de PostgreSQL, un sistema de gestión de bases de datos relacionales de código abierto famoso por su escalabilidad...
Bases de datos NoSQL
1. ¿Qué es una base de datos NoSQL?
Las bases de datos NoSQL (Not Only SQL) representan una alternativa a los sistemas tradicionales de gestión de bases de datos relacionales. Están diseñadas para ofrecer mayor flexibilidad, escalabilidad y mejor rendimiento, lo que las hace especialmente adecuadas para las necesidades de Big Data y las aplicaciones en tiempo real.
A diferencia de las bases de datos relacionales, con sus esquemas fijos, las bases de datos NoSQL pueden almacenar datos de forma no estructurada o semiestructurada. Las hay de varios tipos: orientadas a documentos (MongoDB), clave-valor (Redis), en columnas (Cassandra) y gráficas (Neo4j).
En el contexto de la Business Intelligence, las bases de datos NoSQL ofrecen varias ventajas significativas:
-
Destacan en la gestión de datos no estructurados, permitiendo el análisis de diversas fuentes, como redes sociales o registros de servidores.
-
Algunas bases de datos NoSQL están optimizadas para el análisis en tiempo real de grandes volúmenes de datos, lo que facilita la creación de cuadros de mando dinámicos.
-
Sirven eficazmente como data lakes para integrar datos de múltiples fuentes y ofrecen una gran flexibilidad en la gestión de esquemas.
-
Su escalabilidad horizontal las hace especialmente adecuadas para proyectos de BI que impliquen grandes volúmenes de datos.
-
Las bases de datos gráficas...
Almacenes de datos
1. ¿Qué es un almacén de datos?
Un almacén de datos (Data Warehouse en inglés) es un sistema especializado de gestión de datos diseñado para apoyar las actividades de inteligencia empresarial (BI) y análisis. Se diferencia de las bases de datos operativas tradicionales por su capacidad para consolidar y almacenar grandes cantidades de datos históricos procedentes de fuentes heterogéneas.
El principal objetivo de un almacén de datos es ofrecer una visión coherente y a largo plazo de los datos de la empresa, que permita realizar análisis complejos sin afectar a los sistemas operativos. A diferencia de los sistemas de procesamiento de transacciones, los almacenes de datos están optimizados para las consultas analíticas y el almacenamiento de datos históricos.
Los almacenes de datos se caracterizan por cuatro aspectos fundamentales:
-
Orientación temática: los datos se organizan en torno a temas empresariales clave, como ventas, finanzas o marketing. Esta estructura facilita el análisis de los datos desde el punto de vista de la empresa, ofreciendo una imagen coherente en un momento dado.
-
Integración: un almacén de datos consolida la información procedente de diversas fuentes, como bases de datos relacionales, archivos planos y registros de transacciones en línea. Esta integración garantiza la coherencia de los datos en toda la organización.
-
No volatilidad: una vez integrados en el almacén, los datos permanecen estables y, por lo general, no se modifican. Las actualizaciones se realizan periódicamente desde los sistemas operativos, pero los datos existentes en el almacén ni se actualizan ni se borran, preservando así la integridad histórica.
-
Varianza temporal: a diferencia de los sistemas operativos, que se centran en los datos más recientes, los almacenes de datos están diseñados para analizar la evolución de los datos a lo largo del tiempo. Esto permite identificar tendencias y realizar análisis históricos...
Servidores FTP/SFTP
1. ¿Qué es FTP?
FTP (File Transfer Protocol) es un protocolo de red cliente/servidor utilizado para transferir archivos a través de Internet. Los clientes FTP se utilizan para enviar y recuperar archivos desde servidores que almacenan archivos y responden a las peticiones de los clientes.
Históricamente, FTP ha sido una forma popular de mover archivos grandes entre sistemas o entre ordenadores de escritorio y sistemas. FTP es también una forma común de compartir un archivo cuando es demasiado grande para adjuntarlo en un correo electrónico, subiéndolo a una ubicación neutral para el acceso de otros sistemas, software o individuos. El cliente profesional WS_FTP de Progress se desarrolló en 1994 como uno de los primeros clientes FTP disponibles comercialmente. Sin embargo, desarrollado en una época en la que había menos problemas de seguridad, el protocolo FTP carecía de las características de seguridad y gestión de archivos que son esenciales hoy en día para el intercambio de datos empresariales.
2. ¿Qué es SSH?
Secure FTP se desarrolló en respuesta a la necesidad de mejorar la seguridad a través de túneles. Utiliza Secure Shell 2 (SSH2), un protocolo de túnel seguro, para emular una conexión FTP y proporciona un canal cifrado y fácil de usar para transferencias de archivos utilizando...
Interfaz de programación de aplicaciones (API)
1. ¿Por qué utilizar una interfaz de programación de aplicaciones?
En esta sección, utilizaremos interfaces de programación de aplicaciones (Application Programming Interface en inglés, más conocidas como API) para solicitar datos. Las API son conjuntos de definiciones y protocolos que permiten a las aplicaciones comunicarse entre sí.
En el campo del análisis de datos, las API se utilizan para acceder a datos de distintas fuentes, como bases de datos, archivos o servicios web (algunos de los más conocidos son X, Facebook, Github, eBay, Notion, etc.). También pueden utilizarse para compartir datos con otras aplicaciones.
Las API son especialmente útiles, por ejemplo, en los siguientes casos:
-
Cuando es necesario integrar datos en tiempo real procedentes de múltiples fuentes: las API pueden agregar flujos de datos dinámicos procedentes de sistemas dispares, ofreciendo a los analistas la posibilidad de realizar análisis actualizados continuamente.
-
Cuando se quiere automatizar y optimizar los procesos de extracción de datos: reducen la necesidad de intervención manual y eliminan los errores humanos al permitir programar fácilmente la extracción de datos y adaptarla a las actualizaciones periódicas de BI.
-
Cuando quiera compartir sus datos con otros: las API le permiten compartir sus datos con otras aplicaciones, facilitando la colaboración y la comunicación.
2. Algunas definiciones y un poco de teoría
Empecemos con una definición sencilla.
Una API es un conjunto de protocolos y herramientas que permiten a distintas aplicaciones informáticas comunicarse entre sí. Las API facilitan la integración de servicios, el intercambio de datos y la ampliación de funcionalidades entre distintas aplicaciones. Son esenciales para muchos usos distintos, como la sincronización de datos, la automatización del marketing, las asociaciones entre plataformas, la incorporación de funcionalidades externas y el intercambio de datos abiertos (open data). Las API desempeñan un papel crucial en la interconexión de los sistemas digitales modernos.
Cuando queremos recibir datos de una API, tenemos que hacer una petición. Las peticiones se utilizan en toda la Web. Por ejemplo, cuando consultó...
Web scraping
En esta parte, vamos a descubrir cómo rescatar datos que no se pueden recuperar directamente de una base de datos o un archivo plano. A veces es un poco más complicado encontrar la información de forma condensada.
El web scraping es una técnica para recuperar información de una página web. Como de costumbre, vamos a proceder con dificultad creciente. En la mayoría de los casos, vamos a utilizar una combinación de dos bibliotecas de Python: requests y bs4 (en particular BeautifulSoup). requests se utiliza para descargar el código fuente de la página web y BeautifulSoup se utiliza para navegar a través de la estructura de árbol de la página para acceder a los elementos solicitados.
Cada vez más sitios web crean contenido dinámico, lo que complica un poco nuestra tarea. En este caso, necesitamos utilizar la biblioteca selenium.
A veces, el sitio que contiene los datos que nos interesan intentará limitarnos (y es normal, es una técnica que hay que utilizar con moderación). Entonces tendremos que utilizar varias técnicas para simular varios usuarios diferentes.
Empecemos con un recordatorio sobre HTML y CSS. Es esencial comprender la estructura de una página para saber cómo recuperar su contenido de forma eficaz.
1. HTML/CSS básico
a. HTML (HyperText Markup Language)
HTML es el lenguaje de marcado estándar utilizado para crear páginas web. Cada elemento HTML se define mediante etiquetas, como <tag>contenido</tag>. Las etiquetas pueden contener atributos que proporcionan información adicional.
Un ejemplo sencillo de etiqueta HTML:
<!DOCTYPE html>
<html>
<head>
<title>Page Title</title>
</head>
<body>
<h1>This is a heading</h1>
<p>This is a paragraph.</p>
</body>
</html> b. CSS (Cascading Style Sheets)
CSS se utiliza para dar estilo y formato a los elementos HTML. Sirve para definir el color, la fuente, el diseño, etc. de los elementos de la página.
Un ejemplo sencillo de regla CSS:
body {
background-color: #f0f0f0; ...