
Crear un Data Warehouse
Introducción
Tras haber preparado y depurado cuidadosamente nuestros datos en el capítulo Preparar sus datos para sacarles todo su potencial, estamos listos para dar un paso decisivo: construir un modelo de datos sólido y eficiente dentro de nuestro Data Warehouse (DWH). Esta fase es crucial, porque transforma nuestros datos brutos en un recurso estratégico que permite realizar análisis en profundidad y tomar decisiones basadas en información fiable y estructurada.
En este capítulo exploraremos los fundamentos teóricos y prácticos del modelado de datos, centrándonos en las técnicas específicas de los Data Warehouses. Examinaremos distintos enfoques de modelización, como el esquema en estrella y el esquema en copo de nieve, y hablaremos de su pertinencia en distintos contextos de uso.
También examinaremos conceptos clave como las tablas de hechos y las tablas de dimensiones, esenciales para organizar los datos de forma eficiente y facilitar los análisis multidimensionales. Se prestará especial atención a la optimización del rendimiento de las consultas y a la escalabilidad de los modelos, aspectos cruciales para gestionar grandes volúmenes de datos.
La última parte del capítulo (sección Proyecto Data Warehouse) se dedicará a poner en práctica estos conceptos. Le guiaremos a través de un proyecto concreto...
Las características y ventajas de un Data Warehouse
1. Las principales características
Un Data Warehouse tiene cuatro características clave que lo convierten en una potente herramienta de análisis y toma de decisiones:
-
Orientado a un tema: a diferencia de las bases de datos transaccionales centradas en las operaciones cotidianas, un DWH está diseñado para responder a preguntas analíticas específicas de un ámbito empresarial. Almacena datos vinculados a un tema concreto (clientes, productos, ventas, etc.), excluyendo la información que no es relevante para el análisis. Este enfoque temático permite visualizar los datos de forma simple y concisa, optimizándolos para responder a las necesidades de toma de decisiones.
-
Integrado: un DWH centraliza los datos procedentes de distintas fuentes de la organización, ya sean internas (sistemas CRM, ERP) o externas. Establece una convención de nombres y atributos comunes para garantizar la coherencia y normalización de los datos. Este proceso de integración facilita la búsqueda, recuperación y análisis de la información, proporcionando una visión unificada y fiable de todos los datos de la empresa.
-
Varía con el tiempo: un DWH conserva un historial completo de los datos, lo que permite analizar las tendencias y los cambios durante largos periodos. Los datos se organizan en periodos...
Los componentes de una arquitectura analítica
Los componentes de una arquitectura analítica moderna forman un ecosistema complejo e interconectado, cada uno de los cuales desempeña un papel crucial en el tratamiento y la explotación de los datos. Entre estos componentes destacan tres elementos clave: el Data Lake, el Staging Area y el Data Warehouse, a los que se añaden conceptos complementarios como los Data Marts y metodologías de modelización como Data Vault.
El Data Lake representa una evolución significativa en el almacenamiento de datos. A diferencia de los enfoques tradicionales, permite almacenar volúmenes masivos de datos en su formato bruto, ya sean estructurados, semiestructurados o no estructurados. Esta flexibilidad es especialmente valiosa en la era del Big Data, en la que la diversidad de fuentes y formatos de datos no deja de crecer. El Data Lake ofrece una notable escalabilidad, pudiendo albergar datos tan variados como transacciones, registros de aplicaciones, archivos multimedia o datos IoT.
Una de las principales ventajas del Data Lake es su enfoque schema-on-read, que permite almacenar los datos sin necesidad de transformación previa. Esta característica facilita la rápida ingestión de grandes cantidades de datos, lo que permite procesarlos y analizarlos bajo demanda. Esto ofrece una gran agilidad a los científicos y analistas de datos, que pueden explorar...
Los diferentes tipos de arquitectura de un proyecto analítico
1. Arquitectura Single Tier
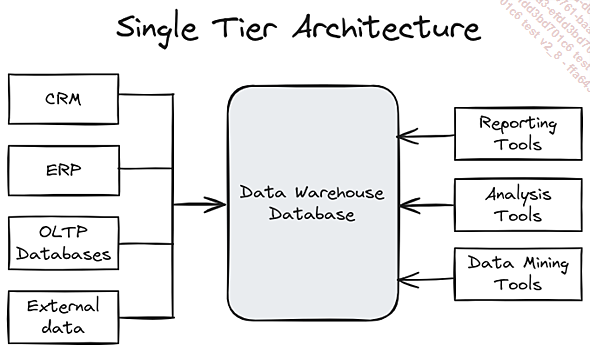
La arquitectura Single Tier o One Tier, también conocida como arquitectura de un solo nivel, representa la configuración más básica de un Data Warehouse. Este enfoque simplista reúne todos los componentes esenciales -almacenamiento, procesamiento y presentación de datos- en un único sistema o servidor. Aunque esta configuración puede parecer atractiva por su aparente sencillez, tiene importantes limitaciones que la convierten en una opción subóptima para la mayoría de los proyectos analíticos modernos.
En esta configuración, los datos se extraen directamente de sus fuentes originales y se copian tal cual en el Data Warehouse, sin pasar por ninguna etapa intermedia de transformación u optimización. Este enfoque «en bruto» significa que los datos no se preparan específicamente para las necesidades analíticas, lo que puede complicar su posterior explotación. Las herramientas de Business Intelligence se conectan directamente a este Data Warehouse centralizado para generar informes y paneles de control. Esta conexión directa, aunque sencilla de configurar, puede crear una carga de trabajo considerable en el sistema único, sobre todo cuando se ejecutan consultas complejas o se generan visualizaciones elaboradas.
A pesar de sus inconvenientes, la arquitectura One Tier tiene ciertas ventajas que pueden hacerla atractiva en contextos específicos. Su sencillez de implantación es innegable: con todos los componentes en un único sistema, la instalación y configuración iniciales son relativamente sencillas. Este enfoque también puede dar lugar a costes iniciales más bajos, ya que el uso de un único servidor limita la inversión en hardware y software al inicio del proyecto. Para las organizaciones pequeñas o los proyectos de tamaño modesto, la centralización también puede simplificar el mantenimiento y la administración del sistema, ofreciendo una facilidad de gestión significativa.
Sin embargo, las limitaciones de esta arquitectura se ponen rápidamente de manifiesto a medida que los requisitos analíticos se hacen más complejos. La falta de separación de funciones crea un cuello de botella...
Normalización/desnormalización
La normalización y la desnormalización son dos enfoques fundamentales del diseño de bases de datos, ofreciendo cada uno de los cuales ventajas específicas en función del contexto de uso. La normalización es un proceso de estructuración de datos diseñado para eliminar la redundancia y garantizar la integridad de los mismos. Consiste en descomponer tablas complejas en tablas más pequeñas y específicas, cada una de las cuales conteniendo únicamente información directamente relacionada con su tema principal. Este proceso, generalmente aplicado hasta la tercera forma normal (3NF), que garantiza que todas las dependencias entre datos están directamente vinculadas a la clave principal de la tabla y que no existen dependencias transitivas, reduce la duplicación de datos, facilita las actualizaciones y minimiza las anomalías. Sin embargo, en un contexto de análisis en el que el rendimiento de lectura es crucial, la normalización puede dar lugar a una multiplicación de las uniones, lo que puede ralentizar las consultas complejas.
Por el contrario, la desnormalización es una técnica que consiste en combinar tablas o añadir datos redundantes para optimizar el rendimiento de la lectura. Este enfoque es especialmente pertinente en los entornos de Data Warehousing y análisis de datos, donde...
Diferentes métodos de diseño de DWH
1. Metodología de diseño Inmon

La metodología Inmon, también conocida como enfoque top-down, es una estrategia de diseño de Data Warehouse que aboga por una visión holística e integrada de los datos corporativos. Desarrollada por Bill Inmon, considerado el «padre del data warehousing», este enfoque se caracteriza por su voluntad de crear una única fuente de verdad para toda la organización.
En el corazón de la metodología de Inmon se encuentra el concepto de Enterprise Data Warehouse (EDWH), un repositorio centralizado que agrega y normaliza los datos de todos los sistemas operativos de la empresa. El EDWH se diseña de acuerdo con un modelo de datos de empresa estandarizado, generalmente hasta la tercera forma normal (3NF), que garantiza una estructura coherente y minimiza la redundancia de datos.
A partir de este EDWH, se derivan Data Marts temáticos para satisfacer las necesidades específicas de los distintos departamentos o áreas de actividad. Estos Data Marts se consideran subconjuntos del Data Warehouse central, lo que garantiza la coherencia general de los datos en toda la organización.
Una de las principales ventajas de la metodología Inmon es su capacidad para proporcionar una visión unificada y coherente de los datos de la empresa. Este enfoque facilita enormemente la toma de decisiones estratégicas al proporcionar una comprensión exhaustiva y fiable de las actividades de la organización. Además, la normalización de los datos en el EDWH permite una gestión eficaz de las actualizaciones y modificaciones, al tiempo que optimiza el espacio de almacenamiento.
Sin embargo, la aplicación de la metodología de Inmon puede resultar compleja y costosa, sobre todo para organizaciones de tamaño medio o proyectos que deban ponerse en marcha rápidamente. El tiempo y los recursos necesarios para definir un modelo completo de datos empresariales e implantar un EDWH a gran escala pueden ser considerables. Además, este enfoque requiere un profundo conocimiento de los procesos de negocio de la empresa desde el inicio del proyecto, lo que puede limitar su flexibilidad ante los rápidos cambios organizativos.
La metodología de Inmon es especialmente adecuada para grandes organizaciones con necesidades...
Los distintos tipos de tablas en un Data Warehouse
1. Las tablas de hechos (fact tables)
Las tablas de hechos son el corazón de la modelización dimensional y contienen las medidas cuantitativas generadas por los sistemas operativos de la empresa. Estas medidas son esenciales para el análisis y la toma de decisiones, ya que permiten crear agregaciones y responder a preguntas clave sobre el rendimiento de la empresa.
Las tablas de hechos se identifican generalmente mediante una clave primaria compuesta, formada por la combinación de las claves externas de las tablas de dimensiones asociadas. Esta clave compuesta garantiza la unicidad de cada registro de la tabla de hechos y permite vincular las medidas a las dimensiones correspondientes.
Tipos de columnas de datos:
-
Aditivos: estas medidas pueden sumarse en todas las dimensiones. Por ejemplo, la cantidad de productos vendidos puede sumarse en todas las dimensiones (tiempo, producto, cliente, etc.).
-
Semi-aditivos: estas medidas pueden sumarse en algunas dimensiones, pero no en todas. Por ejemplo, las existencias de un producto pueden sumarse en la dimensión producto, pero no en la dimensión tiempo (porque las existencias varían con el tiempo).
-
No aditivas: estas medidas no pueden sumarse en ninguna dimensión. Por ejemplo, el precio unitario de un producto o el tipo de descuento no pueden sumarse.
Tipos de tablas de hechos:
-
Tablas de hechos transaccionales: estas tablas capturan...
Esquemas
1. Star Schema (esquema en estrella)
El Star Schema es el esquema más utilizado en la modelización dimensional. Su estructura sencilla e intuitiva facilita la organización de los datos en el Data Warehouse. Consta de una tabla de hechos central, rodeada de tablas de dimensiones vinculadas a ella mediante claves externas.

Esta forma de construir su base tiene varias ventajas:
-
Sencillez: el Star Schema es fácil de entender y utilizar, por lo que resulta ideal para usuarios empresariales que no son necesariamente expertos en bases de datos.
-
Rendimiento: las consultas en un Star Schema suelen ser más rápidas que en otros esquemas, ya que implican menos uniones entre tablas.
-
Fácil de consultar: la sencilla estructura del Star Schema facilita la escritura de consultas SQL para extraer y analizar datos.
Sin embargo, esta estructura no está exenta de posibles problemas:
-
Redundancia de datos: el Star Schema puede provocar cierta redundancia de datos en las tablas de dimensiones, lo que puede aumentar el espacio de almacenamiento necesario.
-
Limitaciones de modelización: el Star Schema puede no ser adecuado para modelizar relaciones complejas entre dimensiones.
2. Snowflake Schema (esquema de copo de nieve)
El Snowflake Schema es una extensión del Star Schema que normaliza las tablas de dimensiones en tercera forma normal (3NF). Esto significa que los atributos de las dimensiones se descomponen en varias...
Proyecto Data Warehouse
En este proyecto, creará un Data Warehouse de la A a la Z usando Python y PostgreSQL. Utilizaremos un conjunto de datos de Kaggle suministrado por una cadena de supermercados brasileña (Olist). Hay dos versiones de este conjunto de datos, el modelo relacional en forma de archivo SQLite y un conjunto de archivos CSV.
Su cliente quiere crear informes semanales sobre el seguimiento de los pedidos. La idea es utilizar este modelo relacional como punto de partida y formatearlo para crear un DWH tipo Kimball centrado en los pedidos.
1. Requisitos previos
Lo primero que hay que hacer para crear este datawarehouse es instalar PostgreSQL y crear una base de datos en blanco. En el momento de escribir este libro, la última versión de PostgreSQL es la 17, que es la que utilizaremos en este proyecto.
Llevaremos a cabo las siguientes acciones:
Instale postgreSQL.
Cree un usuario.
Cree una base de datos.
a. Ubuntu
Paso 1: descarga e instalación de PostgreSQL 17
El primer paso es ejecutar el siguiente comando:
sudo apt-get -y install postgresql-17 Puede comprobar que la instalación funciona correctamente ejecutando el siguiente comando: sudo su - postgres then psql.
Paso 2: añadir un usuario
Pasando a la segunda etapa, tenemos que crear un usuario.
postgres=# CREATE USER user WITH PASSWORD 'contraseña'; Paso 3: añadir una base de datos
Por último, podemos crear nuestra base de datos.
postgres=# CREATE DATABASE projet OWNER user; Ahora podemos comprobar que la base de datos ha sido creada. El comando \l muestra la lista de bases de datos existentes:
postgres=# \l
Name | Owner | Encoding | Collate | Ctype |
Access privileges
-----------+----------+----------+-------------+-------------+
-----------------------
postgres | postgres | UTF8 | fr_FR.UTF-8 | fr_FR.UTF-8 |
projet | user | UTF8 | fr_FR.UTF-8 | fr_FR.UTF-8 |
template0 | postgres | UTF8 | fr_FR.UTF-8 | fr_FR.UTF-8 |
=c/postgres +
| | | | ...