
PL/SQL en objetos de la base de datos
Introducción
Además de los bloques PL/SQL anónimos utilizados por SQL*Plus o por las herramientas de desarrollo (Oracle*Forms, Oracle*Reports...), se puede emplear código PL/SQL en determinados objetos de la base de datos, como los procedimientos almacenados (PROCEDURE, FUNCTION, PACKAGE) y los triggers de base de datos.
Los triggers de bases de datos
Un trigger es un bloque PL/SQL asociado a una tabla. Este bloque se ejecutará cuando se aplique a la tabla una instrucción DML (INSERT, UPDATE, DELETE).
El bloque PL/SQL que constituye el trigger puede ejecutarse antes o después de la actualización y, por lo tanto, antes o despues de la verificación de las restricciones de integridad.
Los triggers ofrecen una solución procedimental para definir restricciones complejas o que tengan en cuenta datos procedentes de varias filas o de varias tablas, como por ejemplo para garantizar el hecho de que un cliente no pueda tener más de dos pedidos no pagados. Sin embargo, los triggers no deben emplearse cuando sea posible establecer una restricción de integridad. En efecto, las restricciones de integridad se definen en el nivel de tabla y forman parte de la estructura de la propia tabla, por lo que la verificación de estas restricciones es mucho más rápida. Además, las restricciones de integridad garantizan que todas las filas de las tablas respetan dichas restricciones, mientras que los triggers no tienen en cuenta los datos ya contenidos en la tabla en el momento de definirlos.
El bloque PL/SQL asociado a un trigger se puede ejecutar para cada fila afectada por la instrucción DML (opción FOR EACH ROW), o una única vez para cada instrucción DML ejecutada (opción predeterminada).
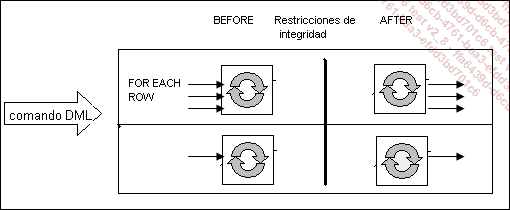
Ejecución antes o después de la comprobación de las restricciones de integridad para cada fila o cada sentencia
En los triggers BEFORE y FOR EACH ROW se pueden modificar los datos que van a insertarse en la tabla, de modo que respeten las restricciones de integridad. También es posible ejecutar consultas de tipo SELECT sobre la tabla a la que se aplica la instrucción DML, aunque únicamente en el marco de un trigger BEFORE INSERT. Todas estas operaciones no se pueden realizar en los triggers AFTER, ya que después de la verificación de las restricciones de integridad no es posible modificar los datos y, dado que la modificación (adición o eliminación) de la fila no se ha terminado, no es posible ejecutar consultas de tipo SELECT sobre la tabla.
También se pueden incluir triggers en las vistas (VIEW) con el fin de capturar las instrucciones DML que se pueden ejecutar sobre ellas. Estos triggers permiten controlar...
Triggers sobre sucesos del sistema o de usuario
Es posible utilizar triggers para hacer un seguimiento de los cambios de estado del sistema, como por ejemplo el arranque y el apagado. Estos triggers van a permitir mejorar la gestión de la base de datos y de la aplicación. En efecto, determinados sucesos del sistema o del usuario tienen una repercusión directa sobre el rendimiento de la aplicación y/o la coherencia de los datos.
Los sucesos del sistema son el arranque y la desconexión de la instancia de Oracle (startup y shutdown) y el tratamiento de los errores. Los triggers de arranque y de desconexión tienen como ámbito el conjunto de la instancia de Oracle, mientras que el trigger de tratamiento de errores puede definirse en el nivel de esquema o en el nivel de base de datos.
En el caso de sucesos de usuario, pueden existir triggers para las operaciones de inicio y cierre de sesión (logon y logoff), y para supervisar y controlar la ejecución de las instrucciones DDL (CREATE, ALTER y DROP) y DML (INSERT, UPDATE y DELETE).
Los triggers DML se asocian a una tabla y a una instrucción DML. Su definición y uso se ha detallado anteriormente en este capítulo.
Al escribir estos triggers, es posible emplear atributos para identificar de forma precisa el origen del suceso y adaptar el tratamiento necesario en consecuencia.
1. Atributos
ora_client_ip_address
Permite conocer la dirección IP del equipo cliente que actúa como origen de la conexión.
ora_database_name
Nombre de la base de datos.
ora_des_encrypted_password
Permite conocer las descripciones cifradas de contraseñas del usuario que se hayan creado o modificado.
ora_dict_obj_name
Nombre del objeto sobre el que acaba de ejecutarse la operación DDL.
ora_dict_obj_name_list
Permite conocer la lista de todos los nombres de objetos que se han modificado.
ora_dict_obj_owner
Propietario del objeto sobre el que se aplica la operación DDL.
ora_dict_obj_owner_list
Permite conocer la lista de todos los propietarios de los objetos que se han modificado.
ora_dict_obj_type...
Modificaciones en los triggers
Un trigger de base de datos no puede modificarse. Sin embargo, puede borrarse para volver a crearlo a continuación, o crearlo mediante la opción OR REPLACE.
La instrucción ALTER TRIGGER permite desactivar y después reactivar los triggers. La desactivación puede planificarse cuando vaya a realizarse una importación masiva de datos o una modificación importante.
La desactivación y la reactivación de triggers pueden realizarse trigger por trigger, o tabla por tabla. La instrucción ALTER TABLE permite activar y desactivar todos los triggers aplicados sobre una tabla.
Sintaxis
ALTER TRIGGER nombre_trigger {ENABLE|DISABLE};
ALTER TABLE nombre_trigger { ENABLE|DISABLE } ALL TRIGGERS;
Ejemplo
Desactivación seguida de una reactivación de triggers:
SQL> alter trigger bf_ins_pedidos DISABLE;
Trigger modificado.
SQL> ALTER TRIGGER bf_ins_pedidos ENABLE;
Trigger modificado.
SQL> ALTER TABLE pedidos DISABLE ALL TRIGGERS;
Tabla modificada.
SQL> ALTER TABLE pedidos ENABLE ALL TRIGGERS;
Tabla modificada.
SQL>
Para obtener información sobre los triggers, es necesario consultar el diccionario de datos. Las tres vistas del diccionario que hay que utilizar son: USER_TRIGGERS, ALL_TRIGGERS y DBA_TRIGGERS.
La columna BASE_OBJECT_TYPE permite...
Procedimientos almacenados
Un procedimiento almacenado es un bloque de código PL/SQL nominado, almacenado en la base de datos y que se puede ejecutar desde aplicaciones u otros procedimientos almacenados. En un bloque PL/SQL, basta con hacer referencia al procedimiento por su nombre para ejecutarlo. En SQL*Plus, se puede utilizar la instrucción EXECUTE.
Sintaxis
CREATE [OR REPLACE] PROCEDURE nombre_procedimiento
[(parámetro {IN/OUT/IN OUT} tipo, ...)]
{IS/AS} bloque PL/SQL; OR REPLACE
Reemplaza la descripción del procedimiento, si existe.
parámetro
Especifica una variable pasada como parámetro que puede utilizarse en el bloque.
IN
El parámetro que se pasa es un dato de entrada para el procedimiento.
OUT
El procedimiento asigna un valor al parámetro especificado y lo devuelve al entorno que haya hecho la llamada.
tipo
Tipo de variable (SQL o PL/SQL).
Ejemplo
Procedimiento para eliminar un artículo:
SQL> create or replace procedure elim_art (numero in char) is
2 begin
3 delete from lineasped where refart=numero;
4 delete from articulos where refart=numero;
5 end;
6 /
Procedimiento creado.
SQL>
Uso en SQL*Plus:
SQL> execute elim_art ('AB01')
Procedimiento PL/SQL terminado correctamente.
Uso en un bloque PL/SQL:...
Funciones almacenadas
Al igual que los procedimientos, una función es un fragmento de código PL/SQL, pero la función devuelve un valor. Estas funciones almacenadas se utilizan como las funciones de Oracle.
Sintaxis
CREATE [OR REPLACE] FUNCTION nombre_función
[(parámetro [IN] tipo, …)]
RETURN tipo {IS/AS} Bloque PL/SQL; OR REPLACE
Si la función existe, se reemplaza su descripción.
parámetro
Especifica un parámetro que se pasa como dato de entrada y que se usa como una variable dentro del bloque.
tipo
Tipo de parámetro (SQL o PL/SQL).
RETURN tipo
Tipo del valor devuelto por la función.
Ejemplo
Función factorial:
CREATE FUNCTION factorial (n IN NUMBER)
RETURN NUMBER
IS BEGIN
if n = 0 then
return (1) ;
else
return ((n * factorial (n-1))) ;
end if ;
END ;
Uso en SQL*Plus:
SQL> select factorial(5) from DUAL;
FACTORIAL(5)
------------
120
SQL>
A partir de la versión 11, es posible indicar a Oracle que conserve en memoria el resultado de la llamada a una función. Cuando se activa esta funcionalidad para una función, cada vez que se llama a esta función con valores diferentes de los parámetros, Oracle almacena en caché el valor de los parámetros y el resultado de la función. Cuando más adelante se llama de nuevo a esta función con los mismos valores de los parámetros, se recupera el resultado de la caché en lugar de calcularlo de nuevo.
Para activar esta...
Paquetes
Un paquete es un objeto del esquema que agrupa de forma lógica elementos PL/SQL relacionados tales como tipos de datos, funciones, procedimientos y cursores.
Los paquetes se dividen en dos partes: una cabecera o especificación y un cuerpo (body). La cabecera permite describir el contenido del paquete y conocer el nombre y los parámetros de llamada de las funciones y procedimientos. Pero el código no forma parte de la cabecera o especificación, sino que se incluye en el cuerpo del paquete. Esta separación de especificaciones y código permite implantar un paquete sin que el usuario pueda visualizar el código y permite, además, adaptar el código de forma sencilla para cumplir nuevas reglas.
Los paquetes ofrecen numerosas ventajas:
Modularidad
El hecho de agrupar de forma lógica elementos PL/SQL relacionados hace más fácil la comprensión de los diferentes elementos del paquete y su uso se simplifica enormemente.
Simplificación del desarrollo
Durante el proceso de definición de una aplicación, los paquetes hacen posible definir en la primera etapa del diseño únicamente la cabecera de los paquetes y realizar así las compilaciones. El cuerpo del paquete solo será necesario para ejecutar la aplicación.
Datos ocultos
Con un paquete es posible hacer que determinados elementos no sean visibles para el usuario del paquete. Esto permite crear elementos que solo pueden utilizarse dentro del paquete y que por tanto simplifican la escritura del mismo.
Adición de funcionalidades
Las variables y cursores públicos del paquete existen durante toda la sesión, por lo que es un modo de compartir información entre los diferentes subprogramas en una misma sesión.
Mejora del rendimiento
El paquete se encuentra en memoria desde que se produce una llamada a un elemento que forma parte de él. El acceso a los diferentes elementos del paquete es entonces mucho más rápido que la llamada a funciones y procedimientos independientes.
1. Cabecera
El ámbito de todos los elementos definidos en la especificación del paquete es global para el paquete y local para el esquema del usuario.
La sección de especificación permite precisar qué recursos del paquete podrán emplear las aplicaciones. En esta sección de especificación deben...
Transacciones autónomas
Una transacción es un conjunto de comandos SQL que constituye una unidad lógica de tratamiento. La totalidad de las instrucciones que definen la unidad deben ejecutarse correctamente, o no se ejecutará ninguna instrucción. En determinadas aplicaciones es preciso ejecutar una transacción dentro de otra.
Una transacción autónoma es una transacción independiente que se ejecuta después de otra transacción, la transacción principal. Durante la ejecución de la transacción autónoma, la ejecución de la transacción principal se detiene.
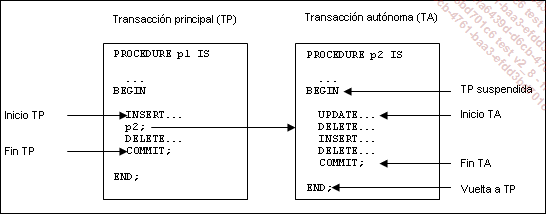
Las transacciones autónomas son totalmente independientes; esta independencia permite construir aplicaciones más modulares. Por supuesto, las transacciones autónomas presentan las mismas características que las transacciones regulares.
Para definir una transacción autónoma hay que emplear la directiva de compilación (pragma) AUTONOMOUS_TRANSACTION. Esta directiva debe aparecer en la sección de declaración de variables de los bloques PL/SQL anónimos, funciones, procedimientos y triggers. Generalmente, las directivas de compilación se incluyen al principio de la sección de declaración de variables, lo que facilita la relectura del programa.
No se puede incluir la directiva de compilación pragma AUTONOMOUS_TRANSACTION en el nivel de paquete. Sin embargo, cada función y procedimiento del paquete se puede declarar como transacción...
SQL dinámico
El SQL dinámico es una técnica que permite crear las sentencias SQL de forma dinámica durante la ejecución del código PL/SQL. El SQL dinámico permite crear aplicaciones más flexibles, ya que los nombres de objeto utilizados por un bloque PL/SQL pueden ser desconocidos en el momento de la compilación. Por ejemplo, un procedimiento puede utilizar una tabla cuyo nombre sea desconocido antes de ejecutar dicho procedimiento.
Debe recordarse que, en el código SQL estático, todos los datos son conocidos en el momento de la compilación y que, por supuesto, las instrucciones SQL estáticas no cambian de una ejecución a otra. Esta solución ofrece sus ventajas, ya que el éxito de la compilación garantiza que las instrucciones SQL hagan referencia a objetos válidos de la base de datos. La compilación también verifica que se dispone de los privilegios necesarios para acceder y para trabajar con los objetos de la base de datos. Además, el rendimiento del código SQL estático es mayor que el del SQL dinámico.
Por estas razones, el SQL dinámico solo debe emplearse si el SQL estático no es capaz de responder a nuestras necesidades o si la solución con código SQL estático es mucho más compleja que con SQL dinámico.
No obstante, el SQL estático tiene ciertas limitaciones que se superan mediante el SQL dinámico. Se utilizará el SQL dinámico si, por ejemplo, no se conocen de antemano las instrucciones SQL que tienen que ejecutarse en el bloque PL/SQL, o si el usuario debe proporcionar datos para construir las instrucciones SQL que hay que ejecutar.
Además, utilizando código SQL dinámico es posible ejecutar instrucciones DDL (CREATE, ALTER, DROP, GRANT y REVOKE), así como los comandos ALTER SESSION y SET ROLE, dentro del código PL/SQL, lo que no es posible con el código SQL estático.
Por tanto, el SQL dinámico se empleará en los siguientes casos:
-
La instrucción SQL no es conocida en tiempo de compilación.
-
La instrucción que se desea ejecutar no está soportada por el código SQL estático.
-
Para ejecutar consultas construidas durante la ejecución.
-
Para hacer referencia a un objeto de la base de datos que no existe en tiempo...
Colecciones y registros
En este capítulo ya se ha visto la declaración e inicialización de colecciones y registros. Este tipo de variables son muy prácticas y un buen conocimiento de su uso permite ahorrar tiempo a la hora de escribir código PL/SQL.
El uso de tablas en PL/SQL no siempre es evidente a primera vista. En efecto, por qué obligar a utilizar esta estructura cuando para almacenar una serie de datos es muy fácil crear una tabla temporal.
La razón es muy simple: al guardar todos los datos en formato de colección directamente en el bloque PL/SQL, todos los tratamientos pueden efectuarse con el motor PL/SQL. Al limitar las consultas SQL, se limitan los accesos a la base de datos, lo que permite acelerar el tiempo de tratamiento del bloque PL/SQL, pero se limita también la ocupación del motor SQL y, en consecuencia, las consultas de los demás usuarios pueden tratarse más rápidamente.
Se observa pues que existen beneficios al trabajar con las colecciones incluso si en un primer momento el código PL/SQL a implementar es algo más complicado. Hay que observar que la instrucción FORALL (que veremos más adelante en este capítulo) permite facilitar considerablemente las etapas de codificación necesarias para poder trabajar con las colecciones en un bloque PL/SQL.
1. Cómo hacer referencia a un elemento de una colección
Para poder trabajar con una colección en primer lugar hay que saber cómo acceder a un elemento de la misma. Todas las referencias emplean la misma estructura: el nombre de la colección seguido de un índice especificado entre paréntesis.
nombre_colección (índice)
El índice tiene que ser un número válido comprendido entre -231+1 y 231-1.
En las colecciones de tipo tabla anidada (nested table) el rango normal de índices va desde 1 hasta 231-1 y para las tablas de tipo VARRAY el rango se define entre 1 y el tamaño máximo de la tabla.
Puede hacerse referencia a un elemento de una colección en cualquier lugar donde pueda emplearse una variable PL/SQL.
Ejemplo
Declaración y uso de una colección:
DECLARE
TYPE lista IS TABLE OF VARCHAR2(15);
losnombres lista:=lista('B Martín','M Burger','S Gatos','T Grueso');
i...Copia de datos por bloques
Completamente integrados con el sistema RDBMS de Oracle, el motor procedimental de PL/SQL procesa todas las instrucciones procedimentales y el motor de SQL procesa todas las instrucciones SQL. Estos dos motores interaccionan con frecuencia, ya que el código PL/SQL trabaja con datos procedentes de la base de datos y los extrae mediante instrucciones SQL.
Cuando se pasa del motor PL/SQL al motor SQL, y viceversa, el servidor tiene una carga de trabajo mayor. Con el fin de mejorar el rendimiento, es importante reducir el número de veces que es necesario cambiar de motor. Las copias de datos por bloques ofrecen una solución que permite reducir el número de interacciones entre estos dos motores.
Reparto del trabajo entre los dos motores:
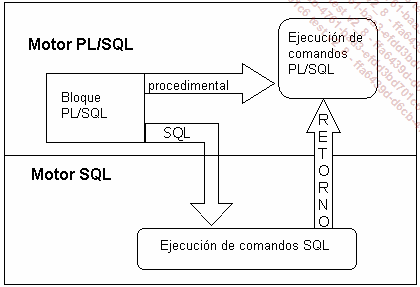
Con la copia por bloques, las instrucciones SQL podrán aplicarse a toda la colección y no solo de forma sucesiva a cada uno de los elementos.
El ejemplo siguiente, en el que se insertan filas en una tabla, permite comparar el tiempo invertido con el procesamiento clásico de las instrucciones SQL en los bloques PL/SQL y el procesamiento por bloques, el cual requiere menos tiempo.
Creación de la tabla Componentes:
SQL> CREATE TABLE Componentes(
2 numero number(5),
3 nombre char(5));
Tabla creada.
SQL>
La tabla creada en el ejemplo anterior se va a rellenar mediante un bloque PL/SQL. Se mide el tiempo de ejecución para cada uno de los métodos de inserción de datos utilizado.
Ventajas del procesamiento por bloques:
SQL> DECLARE
2 TYPE tabla_numeros IS TABLE OF NUMBER(4) INDEX BY BINARY_INTEGER;
3 TYPE tabla_nombres IS TABLE OF CHAR(5) INDEX BY BINARY_INTEGER;
4 LosNumeros tabla_numeros;
5 LosNombres tabla_nombres;
6 t1 number(5);
7 t2 number(5);
8 t3 number(5);
9 PROCEDURE top (t out number) IS
10 BEGIN SELECT TO_CHAR(SYSDATE,'SSSSS') INTO t FROM DUAL; END;
11 BEGIN
12 -- Rellenar las tablas
13 FOR i in 1..5000 LOOP
14 LosNumeros(i):=i; LosNombres(i):=TO_CHAR(i);...Funciones y conjuntos de filas
Ahora es posible definir en PL/SQL funciones que aceptan parámetros de entrada y/o que devuelven no un solo valor, sino un conjunto de filas. La ventaja de estas funciones es que ya no es necesario almacenar los datos en una tabla temporal antes de llamar a la función para que se ejecute. Estas funciones se pueden emplear en todos los casos en que es posible hacer referencia a un nombre de tabla y, especialmente, en la cláusula FROM de una consulta SELECT.
Con el fin de mejorar los tiempos de respuesta de estas funciones que devuelven conjuntos de datos, la cláusula pipelined indica que los datos deben devolverse conforme se ejecuta la función. Además, con este tipo de función, la gestión de los conjuntos de valores devueltos es más sencilla.
En la declaración de la función se añade la palabra clave PIPELINED en la cabecera y los datos se devuelven mediante el comando PIPE ROW.
Estas funciones pueden aceptar como parámetro de entrada un conjunto de filas en forma de colección (por ejemplo una tabla de tipo VARRAY) o en forma de una referencia a un cursor, REF CURSOR.
Ejemplo
El siguiente ejemplo muestra la implementación de una función que devuelve una colección de cifras en modo pipelined, es decir, conforme se ejecuta la función:
SQL> -- creación del tipo
SQL> create type ImpLinea as object( ...La utilidad Wrap
La utilidad Wrap es un programa que permite cifrar el código fuente PL/SQL. De este modo, es posible distribuir código PL/SQL sin que los usuarios puedan tener acceso al código fuente.
Wrap permite enmascarar el algoritmo utilizado, pero en ningún caso se cifran las cadenas de caracteres, números, nombres de variables, columnas y tablas. Por tanto, esta utilidad no permite ocultar las contraseñas o los nombres de las tablas.
Esta utilidad es completamente compatible dentro de Oracle. Sin embargo, la compatibilidad descendente no está asegurada.
Esta utilidad recibe dos parámetros:
iname
Permite especificar el archivo que contiene el código PL/SQL que se va a cifrar.
oname (opcional)
Permite especificar el nombre del archivo que va a contener la versión codificada del archivo especificado en iname. Por omisión, este archivo de salida utiliza la extensión plb.
Sintaxis
wrap iname=archivo_entrada [oname=archivo_salida]
Ejemplo de uso de la utilidad Wrap
DBMS_OUTPUT
El paquete DBMS_OUTPUT permite enviar mensajes desde un procedimiento, una función, un paquete o un trigger de la base de datos.
Los procedimientos PUT y PUT_LINE de este paquete permiten ubicar datos en un búfer que puede leerse desde otro bloque PL/SQL, que empleará el procedimiento GET_LINE para recuperar la información.
Si no se gestiona la recuperación y presentación de los datos incluidos en el búfer y si la ejecución no se realiza bajo SQL*Plus, los datos se ignoran. El principal interés de este paquete es facilitar la depuración de los programas.
SQL*Plus dispone del parámetro SERVEROUTPUT que se activa con la instrucción SET SERVEROUTPUT ON y que permite conocer los datos que se han escrito en el búfer.
1. ENABLE
Este procedimiento permite activar las llamadas a los procedimientos PUT, PUT_LINE, NEW_LINE, GET_LINE y GET_LINES. Si el paquete DBMS_ OUTPUT no está activado, la llamada a este procedimiento se ignorará.
No es necesario llamar a este procedimiento cuando el parámetro SERVEROUTPUT se ha activado desde SQL*Plus.
Sintaxis
DBMS_OUTPUT.ENABLE (tamaño_búfer IN INTEGER DEFAULT 20000) ;
Cuando se especifica, el tamaño máximo del búfer es de 1.000.000 bytes y el mínimo de 2.000 bytes. El valor NULL permite tener un búfer con tamaño ilimitado.
Si se realizan varias llamadas a este procedimiento...
El paquete UTL_FILE
El paquete PL/SQL UTL_FILE permite a los programas PL/SQL llevar a cabo operaciones de lectura y escritura en archivos de texto del sistema de archivos. El flujo de entrada/salida hacia el sistema operativo se limita a trabajar únicamente con estos archivos.
En el servidor, la ejecución del programa PL/SQL que hace uso del paquete UTL_FILE debe realizarse en un modo de seguridad privilegiado, y existen otras opciones de seguridad que limitan las acciones llevadas a cabo a través del paquete UTL_FILE.
Históricamente, en el lado del servidor, los directorios a los que el paquete UTL_FILE podían acceder deben especificarse en el archivo de parámetros (INIT.ORA) usando el parámetro UTL_FILE_DIR.
Sintaxis
UTL_FILE_DIR=c:\temp.
Para hacer que UTL_FILE pueda acceder a todos los directorios del servidor hay que especificar el siguiente parámetro en el archivo INIT.ORA: UTL_FILE_DIR=*
A partir de la versión 9i, es mejor utilizar el comando CREATE DIRECTORY para gestionar los directorios accesibles desde el paquete UTL_FILE, en lugar del parámetro de inicialización UTL_FILE_DIR.
Es posible conocer la lista de directorios definidos en el servidor usando la vista ALL_DIRECTORIES.
Sintaxis
CREATE OR REPLACE DIRECTORY nombre_directorio AS 'ruta';
En el ejemplo de resumen del paquete se proporciona un ejemplo de cómo emplear esta instrucción.
1. FOPEN, FOPEN_NCHAR
Esta función permite abrir un archivo para llevar a cabo operaciones de lectura o de escritura. La ruta de acceso al archivo debe corresponderse con un directorio válido, definido con CREATE DIRECTORY.
La ruta de acceso completa debe existir previamente y el comando FOPEN no puede crear directorios.
La función FOPEN devuelve un puntero al archivo. Este puntero debe especificarse para el conjunto de operaciones de lectura/escritura que se realizarán a continuación.
No se pueden abrir más de 50 archivos simultáneamente.
Sintaxis
UTL_FILE.FOPEN(
ruta IN VARCHAR2,
nombre_archivo IN VARCHAR2,
modo_apertura IN VARCHAR2
tamaño_máximo_fila IN BINARY_INTEGER DEFAULT 1024)
RETURN UTL_FILE.FILE_TYPE;
ruta
Nombre del objeto DIRECTORY que corresponde al directorio del sistema operativo que contiene el archivo que va a abrirse.
nombre_archivo
Nombre del archivo con su extensión, sin incluir ninguna información...
El paquete DBMS_LOB
La abreviatura LOB (Large OBjet) identifica a los objetos de gran tamaño.
Trabajar con elementos de gran tamaño (BLOB: Binary LOB, CLOB: Character LOB, NCLOB: uNicode CLOB y BFILE: archivo binario) no es tan sencillo como trabajar con datos de tipo más clásico (carácter, numérico, fecha). El lenguaje PL/SQL permite trabajar con estos datos desde el momento en que se encuentran en la base de datos, pero las operaciones de carga desde un archivo del sistema operativo, de comparación o de modificación solo podrán realizarse mediante el paquete DBMS_LOB.
1. Constantes
Las siguientes constantes se definen en el paquete DBMS_LOB. Su uso permite aclarar el uso de las distintas funciones y procedimientos del paquete.
file_readonly CONSTANT BINARY_INTEGER :=0;
lob_readonly CONSTANT BINARY_INTEGER :=0;
lob_readwrite CONSTANT BINARY_INTEGER :=1;
lobmaxsize CONSTANT INTEGER :=18446744073709551615;
call CONSTANT PLS_INTEGER :=12;
session CONSTANT PLS_INTEGER :=10;
2. APPEND
Este procedimiento permite añadir la totalidad de la variable LOB de origen a la variable LOB de destino.
Sintaxis
DBMS_LOB.APPEND(
destino IN OUT NOCOPY BLOB,
origen IN BLOB);
DBMS_LOB.APPEND(
destino IN OUT NOCOPY CLOB CHARACTER SET ANY_CS,
origen IN CLOB CHARACTER SET destino%CHARSET);
3. CLOSE
Este procedimiento permite cerrar un elemento LOB interno o externo que se haya abierto anteriormente.
Sintaxis
DBMS_LOB.CLOSE(
{lob_origen IN OUT NOCOPY BLOB
| lob_origen IN OUT NOCOPY CLOB CHARACTER SET ANY CS
| archivo_origen IN OUT NOCOPY BFILE);
4. COMPARE
Esta función permite comparar dos objetos LOB en su totalidad o parcialmente. Únicamente es posible comparar objetos LOB del mismo tipo (BLOB, CLOB o BFILE). Con archivos (BFILE), antes de llevar a cabo la operación de comparación, los elementos deben abrirse con FILEOPEN.
La función COMPARE devuelve 0 si los dos elementos que hay que comparar son completamente idénticos o un valor diferente de cero en caso contrario.
Sintaxis
DBMS_LOB.COMPARE(
lob1...