
Ir más lejos
Introducción
Aunque nuestro objetivo se ha cumplido, nos gustaría darle toda la información posible sobre los próximos pasos, tanto organizativos como técnicos y las posibilidades de mejorar el funcionamiento de nuestra plataforma, hacerla evolucionar y garantizar una mayor seguridad.
Plan de recuperación en caso de catástrofe
1. En caso de catástrofe

Figura 1: Cuando ocurre lo peor
Cuando hablamos de alta disponibilidad, solemos hablar también de recuperación ante desastres, de ahí el término HA-DR (High Availability-Disaster Recovery).
Aunque el objetivo de la alta disponibilidad es garantizar la disponibilidad de las aplicaciones en el mayor número posible de escenarios, también es necesario planificar lo que a veces parece improbable: un fallo importante que provoque la no disponibilidad parcial o total del servicio o, incluso, su destrucción total.
Suele ser una lección que se aprende demasiado tarde: nunca se confíe demasiado. Recuerde la Ley de Murphy: todo lo que puede salir mal, saldrá peor. Y el corolario de Finagle (que es un personaje de ficción): todo lo que pueda salir mal saldrá el peor momento posible. Recordemos también que hay dos tipos de ingenieros de sistemas: los que han cometido un grave error y los que van a volver a cometerlo.
Los autores han tenido la oportunidad de probar varios escenarios en producción real. Los trabajos de producción informática pueden ser angustiosos. ¿Cómo reaccionar cuando se pierde la interconexión entre dos centros de datos? ¿Cómo reaccionar cuando alguien desconecta todos los repartidores de carga al mismo tiempo, cortando así por completo el acceso a todos los servidores?
Cualquier sistema creado por un ser humano está abocado a ser imperfecto. De hecho, la mayoría de los incidentes y accidentes son el resultado de la intervención humana, ya sea involuntaria o no.
Cuando todo va mal, cuando todo se pierde, hay que pensar en el plan B o incluso en el plan C. ¿Cómo se vuelve a la normalidad? Anticipándose a la catástrofe y poniendo en marcha un plan para reanudar los servicios.
El incendio de un centro de datos de OVH en marzo de 2021 es un recordatorio de la importancia de la planificación de la recuperación en caso de desastre y una dura lección para aquellos que creyeron en la magia de la nube, que pensaron que un desarrollador fullstack podía sustituir a un Ops o a un arquitecto, que la redundancia hacía innecesarias las copias de seguridad...
Copias de seguridad
1. Redundancia frente a copia de seguridad
Un RAID, un clúster o cualquier solución redundante no es una copia de seguridad. Una copia local archivada en un disco duro, del mismo servidor o de un servidor de la misma zona, no es una copia de seguridad. No confíe sus datos a un informático que le diga lo contrario.
Es muy importante señalar este hecho evidente. Los sucesos de marzo de 2021, que provocaron la pérdida permanente de miles de sitios web y servicios, e incluso la pérdida de todos los datos de algunas empresas, son otra llamada de atención.

Figura 3: Sin copia de seguridad... La desesperación tras la pérdida de un centro de datos
Ya sea en la nube o en su propio centro de datos, las copias de seguridad son necesarias y vitales. En el mundo digital actual, los datos son un componente vital de cualquier organización, pero no el único. ¿Cuántas tragedias están relacionadas con la pérdida de fotos familiares tras la caída de una aplicación o el fallo de una llave USB, tarjeta de memoria o disco duro?
Las copias de seguridad se deben externalizar: no deben estar ubicadas en el mismo centro de datos que los servidores. Si es posible, deben estar disponibles por duplicado. En la nube, se pueden duplicar volúmenes específicos en varias zonas y regiones para garantizar la disponibilidad. En AWS, por ejemplo, los buckets S3 se pueden replicar entre varias regiones e incluso entre buckets.
Un bucket s3 es una forma de almacenamiento de objetos ofrecida por el proveedor de la nube Amazon. Este almacenamiento es accesible a través del protocolo HTTP.
Lo mismo ocurre en Azure, por supuesto, donde los datos y las copias de seguridad se pueden replicar en varios modelos, dentro de una sola región, en varias zonas y en varias regiones. Las copias de seguridad se deben probar: comprobamos periódicamente que son accesibles y están disponibles y que los datos se pueden restaurar...
Seguridad
1. Contenedor y root
a. Ejemplo de explotación
Desde el principio, y dejando a parte el despliegue del clúster de Galera, hemos desplegado la aplicación eni-todo sin preocuparnos por sus permisos, tanto al construir la imagen como al ejecutarla. Sin embargo, nuestra aplicación se ejecuta con UID 0, como root. También hemos desactivado apparmor en aras de la simplificación.
La mayoría de las imágenes disponibles públicamente, ya sea en Docker Hub o en repositorios Git, no tienen en cuenta la gestión de usuarios: dentro del contenedor, todo o casi todo se ejecuta como root.
Sin embargo, normalmente se aplica el principio del menor privilegio: un producto sólo debe funcionar con los permisos estrictamente necesarios.
Tomemos como ejemplo la sencilla imagen de prueba de Nginx utilizada en el capítulo Configuración de un clúster Kubernetes, y veamos qué podemos hacer con ella.
$ docker run --name some-nginx -d nginx
...
11a90c92c2c3b3507fa5068198a780bf9be39a74df5f427f8a601945c9d15a54 Si abre un shell interactivo dentro de este contenedor, verá que es root.
$ docker exec -ti 11a90c92c2c3 bash
root@11a90c92c2c3:/# id
uid=0(root) gid=0(root) groups=0(root) Esto no significa necesariamente que también podamos obtener permisos de root en el host: el contenedor se ejecuta en su propio espacio de nombres. Nuestro contenedor Nginx está limitado aquí y el riesgo es bajo. Pero por defecto, los contenedores y el host comparten UID y GID. Si, a través de una laguna de seguridad o de un arranque de contenedor construido de cierta manera, el contenedor tiene acceso a los componentes del host, entonces esto se vuelve peligroso. Aquí hay un ejemplo simple usando volúmenes montando el directorio /etc del host dentro del contenedor:
seb@infra01:~$ docker run --name some-nginx -v /etc:/mnt/etc -d
9f4d178c388e3df5e8e0f68137054339e7b0a0fbd8562245ddf4263fd7685cbd
seb@infra01:~$ docker exec -ti 9f4d178c388e3 bash
root@9f4d178c388e:/# echo "seb ALL=(ALL) NOPASSWD: ALL" >
/mnt/etc/sudoers.d/seb
root@9f4d178c388e:/# exit
exit
seb@infra01:~$ sudo -l
User seb may run the following commands on infra01:
(ALL) NOPASSWD: ALL El usuario seb, sin permisos particulares, lanzó un contenedor...
Supervisión
1. Métrica
Las métricas son esencialmente la recopilación de información sobre los procesadores, la memoria, los discos y la red con el fin de comprobar su rendimiento. Gracias a estos valores y a su seguimiento, es posible analizar el consumo de los distintos recursos y actuar en consecuencia:
-
crear nuevos servidores,
-
ampliar el espacio en disco,
-
añadir memoria,
-
mejor distribución de los servicios.
Las métricas se suelen controlar mediante herramientas de supervisión y sondas como Nagios y Centreon, que son gratuitas y protocolos como SNMP. Las herramientas de línea de comandos del sistema como sar, iostat, mpstat, etc. proporcionan información útil.
Kubernetes ofrece un API dedicado a las métricas, que requiere el uso de un controlador complementario opcional. Este API proporciona acceso a nuevas funciones, como el autoescaling (adición y eliminación dinámica de pods en función de la carga).
Para probar esta funcionalidad, es necesario instalar un pipeline de recogida de métricas. Existen dos tipos, en función de si se basan en la recopilación de métricas vinculadas únicamente al clúster, como metrics-server, o en la recopilación de métricas vinculadas a todo el entorno, como Prometheus.
El servidor de métricas está disponible en https://github.com/kubernetes-sigs/metrics-server.
Prometheus es más completo, pero también más complejo, está disponible en https://prometheus.io/.
Puede instalar rápidamente metrics-server de la siguiente manera:
$ kubectl apply -f https://github.com/kubernetes-sigs/
metrics-server/releases/latest/download/components.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-
reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:
auth-delegator...Almacenamiento
En la sección Despliegue con Kubernetes, mencionamos la existencia de varios proyectos para configurar una infraestructura de almacenamiento, basada en una infraestructura Kubernetes.
MinIO ofrece un sustituto de S3 en un clúster Kubernetes.
Proyectos como OpenEBS o GlusterFS despliegan pods con permisos elevados para montar discos o acceder al LVM subyacente, con el fin de utilizar estos nodos Kubernetes como parte del clúster de datos. A continuación, es posible añadir nodos para satisfacer las crecientes necesidades de las aplicaciones.
Rook también es un proyecto de infraestructura de almacenamiento nativo de la nube diseñado para proporcionar operadores de Kubernetes para configurar servidores Ceph, Cassandra o NFS en un clúster.
Aunque los operadores mejoran constantemente y ofrecen mecanismos de reparación, ajuste y actualización cada vez más automatizados, este tipo de herramientas siguen consumiendo muchos recursos en términos de CPU, RAM, red y, por supuesto, acceso de lectura y escritura a los discos que alojan la solución.
Por lo tanto, es muy importante definir claramente sus necesidades y objetivos antes de intentar instalar un CephFS (Ceph File System) en un clúster Kubernetes instanciado en una plataforma OpenStack alojada en un vSphere obsoleto. Tiene que pensar de antemano en los recursos que necesitas.
PaaS
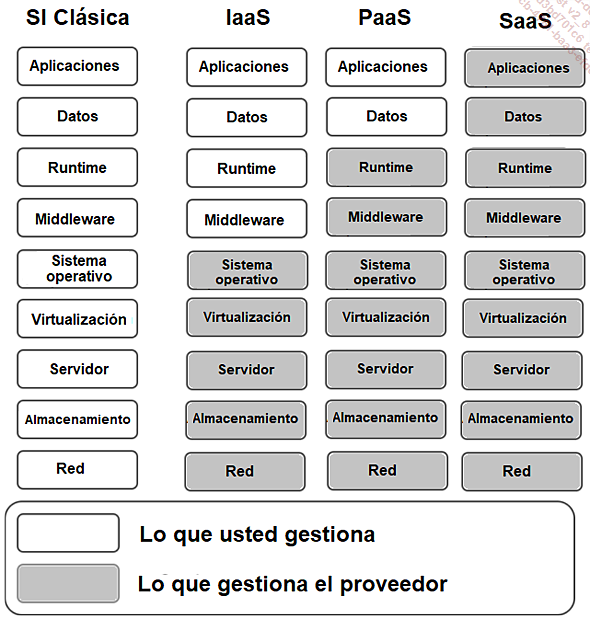
Figura 5: Sistema de información tradicional frente a soluciones IaaS, PaaS o SaaS
Kubernetes ofrece una enorme gama de servicios y facilita enormemente la difícil tarea de configurar una infraestructura de alta disponibilidad.
Hay muchas opciones... ¿Qué motor de red utilizar, qué controlador ingress, qué motor OCI (motor de contenedorización)? ¿Cómo proteger el clúster y garantizar el patch management de las imágenes? ¿Cómo se comprueba la coherencia de todos estos componentes?
Como discutimos en el capítulo de Orquestación, es el papel de las distribuciones gestionar todo esto. La distribución con la que los autores han experimentado más ampliamente es OpenShift de Red Hat.
OpenShift es la primera distribución en impulsar la seguridad por defecto, en particular mediante la prohibición de pods como root por defecto, requiriendo el uso de SELinux y proporcionando un registro Docker seguro y segmentado.
OpenShift también proporciona integración con sus herramientas de supervisión y alerta orientadas a PaaS. La seguridad que proporciona el aislamiento del namespace, cuyo alcance se ha ampliado a los proyectos, se lleva al extremo directamente en sus componentes de infraestructura. Por ejemplo, un usuario con acceso al proyecto A y no al proyecto B, no tendrá acceso a las trazas del proyecto B en el servicio...