
Despliegue con Kubernetes
Introducción
En los capítulos anteriores, vimos cómo construir imágenes Docker de nuestra aplicación y cómo desplegarlas de forma semiautomática en nuestros servidores utilizando scripts de Ansible. Con un orquestador como Kubernetes, ahora sabemos cómo liberarnos de las limitaciones de un entorno estático, dejando que elija dónde desplegar por nosotros. Ahora vamos a ver cómo desplegar eni-todo utilizando este orquestador. Para ello, tenemos que aprender a utilizar ciertos recursos.
Todos los ejemplos de Kubernetes presentados en este capítulo y en los siguientes están disponibles en el repositorio de github k8s_manifests.
Del pod al despliegue
1. Pod
Hemos visto que es posible crear un pod utilizando un contenedor tomcat-eni-todo :v24.04-tomcat-h2-env:dev. Usaremos esta versión primero, añadiendo la externalización de la base de datos más tarde.
Así que lanzamos un pod eni-todo-h2 con el contenedor usando esta imagen. Tenemos que asegurarnos de que el contenedor ha arrancado y funciona correctamente.
$ kubectl run eni-todo-h2 \
--image=registry.diehard.net:5000/tomcat-eni-todo:v24.04-
tomcat-h2-env \
--env="
DB_DTB_JDBC_URL="jdbc:mysql://mariadb.diehard.net:3306/db_todo" \
--env="DB_DTB_USERNAME=springuser" ...
pod/eni-todo-h2 created También puede lanzar el contenedor con un archivo YAML y el siguiente comando:
$ kubectl apply -f eni-todo-h2.000.pod.yaml
pod/eni-todo-h2 created Los archivos YAML utilizados en este capítulo se encuentran en la carpeta src/main/kubernetes del repositorio git de la aplicación eni-todo (https://github.com/halnx-todo/k8s-manifests).
a. Sensores y control de estado
Kubernetes ofrece un sistema de sondas para comprobar el estado (healthcheck) de un pod. Hay tres tipos de sonda:
-
livenessprobe
-
readinessprobe
-
startupprobe
Las tres se configuran de la misma manera, utilizando objetos en la definición del contenedor.
Existen tres posibles mecanismos de sondeo:
-
tcpSocket: el kubelet en el nodo comprueba que el contenedor ha abierto el puerto definido en los parámetros para esta sonda.
-
Exec: el kubelet presente en el nodo comprueba que el script definido en los parámetros de esta sonda se ejecuta correctamente (código de retorno 0) en el contenedor observado.
-
httpGet: el kubelet presente en el nodo comprueba que la llamada HTTP definida en los parámetros de esta sonda, devuelve un código de retorno como el definido (200 por defecto).
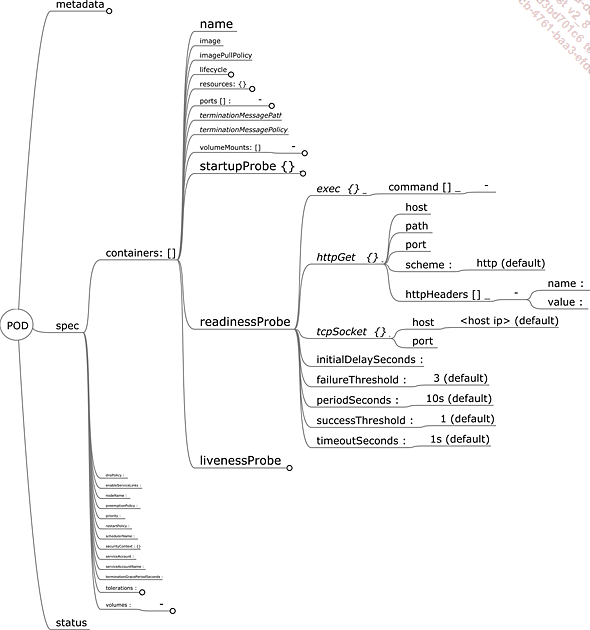
Figura 1: Especificaciones de la sonda de un pod
Las sondas tienen:
-
un retardo antes de activarse (initialDelaySeconds),
-
una frecuencia de ejecución (periodSeconds),
-
un umbral o número de errores (failureThreshold),
-
un tiempo máximo de espera (timeoutSeconds).
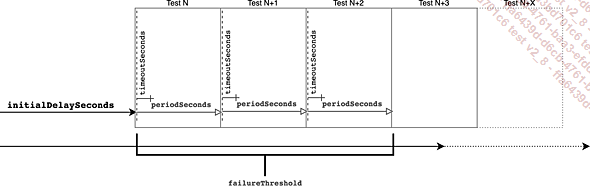
Figura 2: Calendario y frecuencia de los controles de estado
Los tres tipos de sonda tienen mecanismos de análisis idénticos: esperan el retardo inicial...
Servicios y Endpoints
Hemos repasado rápidamente la necesidad de tener varios pods para mantener el servicio, pero es precisamente esta redundancia la que permite mantener esta alta disponibilidad.
Así que necesitamos un mecanismo para distribuir el flujo de peticiones a los pods. Esta es la función de los objetos Service. Esta abstracción se utiliza para proporcionar al clúster la información que necesita para configurar la red para la comunicación dentro del clúster y con el mundo exterior.
Como se ha mencionado en los capítulos anteriores, las etiquetas se utilizan para seleccionar objetos en Kubernetes. El mecanismo de etiquetas es omnipresente en un clúster. Las etiquetas también se utilizan para asociar (mapping) pods a un servicio mediante un selector.
1. Servicio de tipo ClusterIP
Por tanto, un servicio es una abstracción de Kubernetes para permitir la resolución de red y la exposición de pods. El DNS de un servicio es de la forma:
<service>.<namespace>.svc.cluster.local También se puede utilizar un Service para exponer la aplicación en un puerto diferente al expuesto por el pod, si es necesario.
apiVersion: v1
kind: Service
metadata:
labels:
app: eni-todo
name: eni-todo
spec:
ports:
- port: 80
name: http8080
protocol: TCP
targetPort: 8080
selector:
app: eni-todo
sessionAffinity: ClientIP
type: ClusterIP A continuación, puede buscar los pods identificados por las etiquetas.
$ kubectl get po -l app=eni-todo
NAME READY STATUS RESTARTS AGE
eni-todo-95755d699-gldr6 1/1 Running 0 55m
eni-todo-95755d699-jrzrg 1/1 Running 0 55m...Secret y ConfigMap
Hemos visto que escribimos variables de entorno directamente en la definición del pod (pod template). Siempre es mejor externalizar los archivos de configuración, que para eso están ConfigMap y Secret.
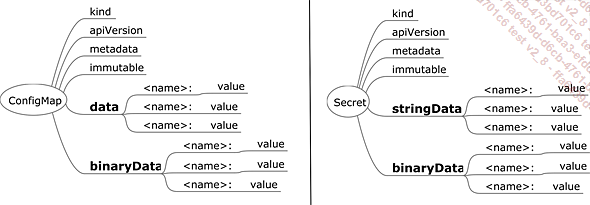
Figura 9: ConfigMaps y Secret
Es posible almacenar pares variable/valor en objetos ConfigMap y Secret. Pero mientras que un ConfigMap almacena información directamente en formato de texto plano, un Secret requiere un valor codificado en formato base64, por ejemplo:
mysql_root_password: cjAwdC1hZWtpZThhaHdhaV8= El almacenamiento en la base de datos etcd también es diferente, ya que los secretos se cifran en la base de datos si la opción está activada en kube-apiserver (--encryption-provider-config).
La codificación en base64 no es un cifrado seguro. Es un cambio del marco de referencia de codificación de la información. La información binaria, que antes era de 8 bits, ahora es de 7. Esta codificación está diseñada para evitar problemas con caracteres especiales que podrían malinterpretarse durante las transferencias de red.
También es posible almacenar archivos en ambos tipos de objetos.
En un ConfigMap:
apiVersion: v1
kind: ConfigMap
metadata:
name: mariadb-init
data:
init.sh: |
#!/bin/sh
if [[ true ]]; then
echo "[mysqld]" >>...StatefulSet
Habiendo visto cómo acceder a una base de datos externa, ahora veremos cómo poner una base de datos en nuestro clúster.
Un pod se puede instanciar en cualquier nodo en función de los recursos disponibles. Si bien esto funciona muy bien para los servicios sin conservación de estado (stateless), no es el caso de las bases de datos, cuya función misma es conservar los datos.
Al inicio de Kubernetes, un truco era forzar la ejecución de un pod en un nodo específico, a través de una selección utilizando el atributo nodeName, o utilizar los mecanismos nodeAffinity o nodeSelector para asegurarse de que un pod se instanciaba en un nodo con directorios dedicados a almacenar los datos del pod, que el pod podía montar directamente utilizando hostpath.
apiVersion: v1
kind: Pod
metadata:
labels:
app: mariadb
name: mariadb
spec:
volumes:
- name: test-volume
hostPath:
path: /data/mariadb
type: DirectoryOrCreate
containers:
- image: mariadb:10.5.8
name: mariadb
nodeName: k8s-worker01
env:
- name: MYSQL_USER
value: "springuser"
- name: MYSQL_PASSWORD
value: "mypassword-quoor-uHoe7z"
- name: MYSQL_DATABASE
value: "db_todo"
- name: MYSQL_ROOT_PASSWORD
value: "r00t-aeKie8ahWai_"
volumeMounts:
- mountPath: /var/lib/mysql
name: test-volume
ports:
- name: mariadb
containerPort: 3306
protocol: TCP No es un truco muy bueno, de hecho, es un hack infame. Pero durante mucho tiempo se utilizó para satisfacer las demandas de los gerentes...
PersistentVolume
Como hemos mencionado varias veces, Kubernetes es un orquestador que selecciona el nodo en el que instanciar el pod de su pool de nodos, según los criterios que le hayamos dado. Esto significa que, para proporcionar persistencia de datos, éstos deben poder ser utilizados por el pod en cualquier nodo. Los contenedores que componen los pods tendrán que montar los volúmenes presentes en su nodo. El propio nodo probablemente tendrá que montar un sistema de s adicional (NFS, Gluster FS, etc.). Los objetos PersistentVolume y PersistentVolumeClaim proporcionan a los clústeres (nodo, kubelet, etc.) la información que necesitan para montar estos diferentes sistemas de s.
Este mecanismo está intrínsecamente ligado a las tecnologías y herramientas subyacentes fuera del clúster. Dicho esto, existen soluciones de almacenamiento que utilizan un clúster Kubernetes, como Rook, GlusterFS u OpenEBS, que dedican espacios de almacenamiento en los nodos del clúster al servicio de almacenamiento, para garantizar la persistencia de los volúmenes de datos que ofrecen y asegurar su coherencia.
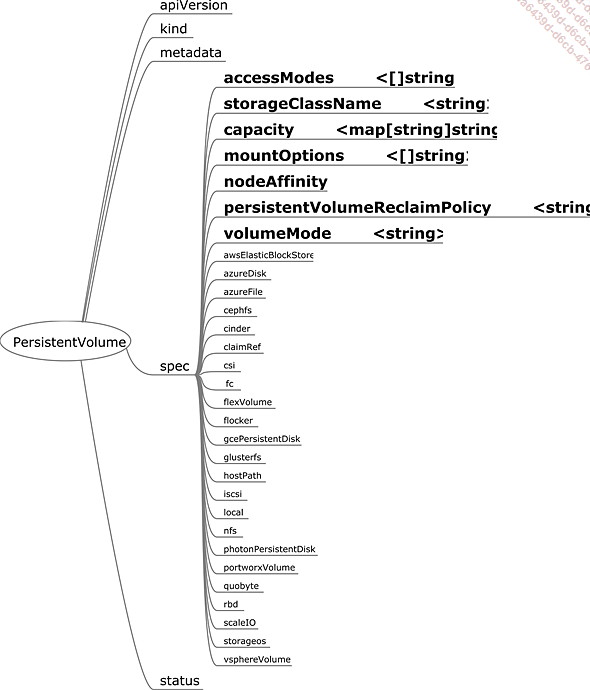
Figura 10: Especificaciones de un volumen persistente
Un volumen persistente (Persistent Volume o PV) tiene varios atributos:
-
accessModes: define el tipo de acceso del pod al volumen, con tres modos posibles. Sus modos son:
-
ReadWriteOnce (RWO): el volumen sólo puede ser leído-escrito...
PersistentVolumeClaim
Una solicitud de volumen persistente (Persistent Volume Claim o PVC) es un tipo de contrato que vincula un volumen persistente a un namespace. Cuando se crea, el clúster Kubernetes busca proporcionar un volumen persistente que se corresponda con las necesidades definidas en la PVC. Si por casualidad dispone de la clase de almacenamiento solicitada, la utiliza para crear un nuevo PVC conforme a la definición de la clase solicitada y a los requisitos definidos en el PVC inicial. En caso contrario, busca en su reserva de volúmenes persistentes el que mejor corresponda a la solicitud.
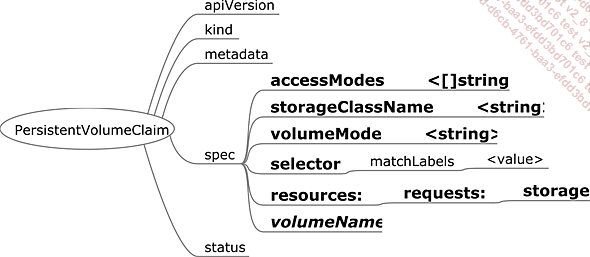
Figura 11: Especificaciones del PVC
Cuando el PV se asigna al PVC, el atributo claimRef del PV se rellena con las referencias del PVC (name).
StorageClass
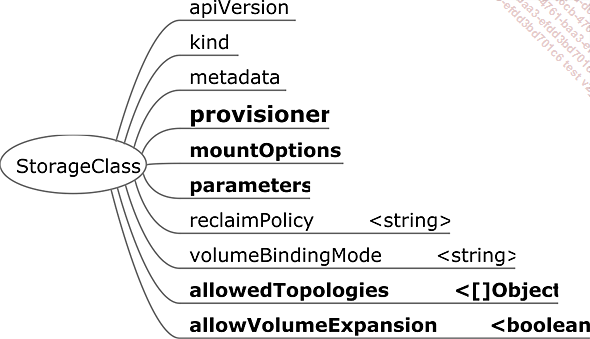
Figura 12: Especificaciones de la clase de almacenamiento
La clase de almacenamiento (StorageClass) es el recurso utilizado para abastecer dinámicamente de los PVC (y los PV detrás de ellos).
Tiene varios atributos:
-
provisioner: el provisioner corresponde al CSI (Container Storage Interface), el controlador utilizado para comunicarse con el servidor de almacenamiento.
-
mountOptions: son las opciones que pasan por el nodo al montar el sistema de s.
-
parameters: son los parámetros requeridos por el controlador.
-
reclaimPolicy: es la definición del ciclo de vida del PV asignado al PV creado con esta clase de almacenamiento (Delete, Retain o Recycle).
-
volumeBindingMode: es la política utilizada para trazar la vinculación del volumen entre el PVC que llama a la clase de almacenamiento y el PV creado por ella.
-
Inmediate: la información que vincula el PV con el PVC se crea antes de que se utilice el PVC.
-
WaitForFirstConsumer: la información que vincula el PV con el PVC la proporciona un nodo cuando se ensambla el volumen.
-
allowedTopologies: son las etiquetas autorizadas para los PV que se van a crear. Este atributo se utiliza principalmente (para los CSI que lo permiten) para garantizar que el volumen se crea en la misma zona o región que el nodo que lo va a montar.
En la nube, por ejemplo, la creación de un PVC con una clase de almacenamiento específica del proveedor crea automática y dinámicamente...
Rutas ingress
1. El controlador del flujo entrante
Como hemos visto antes, los servicios no se adaptan perfectamente a los servidores web y al concepto de alojamiento compartido de servicios web (virtual hostname). Los servicios web se prestan generalmente, por convención, en los puertos 80 y 443. Además, muchos sistemas de seguridad bloquean las llamadas a puertos no estándar.
Para los clústeres Kubernetes alojados por proveedores de servicios en la nube, es posible utilizar servicios de repartidor de carga, pero cada servicio abierto cuesta el precio de un repartidor de carga del proveedor.
El controlador de los flujos de entrada (ingress controller) es un controlador en el sentido de Kubernetes, es decir, escucha los eventos y reacciona a los cambios en determinados tipos de recursos, en nuestro caso, los recursos ingress.
El ingress controller instancia uno o varios pods de reverse proxies con permisos elevados (hostPort, NET_BIND_SERVICE) que pueden, si están configurados para ello, escuchar en los puertos 80 y 443 de los nodos en los que se ejecutan. Estos reverse proxies enrutarán las peticiones HTTP a los servicios apropiados definidos en los recursos de tipo ingress.
Hay muchas instanciaciones posibles de controladores ingress, dependiendo de la tecnología subyacente (Traefik, Nginx, Kong, HAProxy, etc.).
Es posible tener varios controladores ingress y distinguirlos mediante clases (ingressClass) que definen un controlador...
Job y CronJob
Es posible lanzar tareas (jobs) en Kubernetes. Los jobs son únicos: solo se ejecutan una vez.
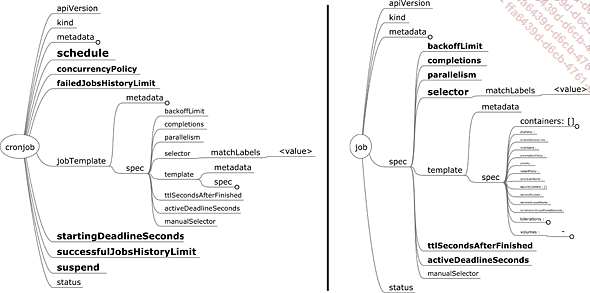
Figura 14: Especificaciones de un Job y CronJob
Los atributos del job son los siguientes:
-
backoffLimit es el número de intentos fallidos (exit !=0) antes de que se considere que el trabajo ha fallado (fail).
-
completions es el número de pods que deben tener éxito (exit == 0) para considerar que el job ha tenido éxito.
-
parallelism es el número de pods que se pueden ejecutar al mismo tiempo.
-
ttlSecondsAfterFinished es el tiempo que hay que esperar antes de dejar que los mecanismos de limpieza eliminen los pods finalizados. Si no se establece el atributo, el job no se eliminará automáticamente.
-
activeDeadlineSeconds define el tiempo que se debe esperar antes de intentar eliminar el trabajo.
También es posible programar tareas recurrentes para determinadas fechas: cronjobs.
Los atributos más importantes de un cronjob son:
-
schedule define en formato cron la periodicidad de ejecución de los jobs.
-
concurrencyPolicy define la política a seguir si la periodicidad solicita el lanzamiento de un nuevo job mientras el job anterior no ha finalizado.
-
Allow permite las ejecuciones al mismo tiempo.
-
Forbid bloquea el nuevo job.
-
Replace cancela el job anterior e inicia el nuevo.
-
suspend define si el cronjob está suspendido (true) o activo (false).
Para eni-todo, por ejemplo, puede usar un cronjob...
DaemonSet
El DaemonSet es un recurso que lanza una única instancia de pod en cada uno de los nodos del cluster correspondientes a su objetivo de selector.
Sus atributos clave son los siguientes:
-
minReadySeconds es el retardo antes de que el conjunto de demonios cuyo pod está ready, se considere ready.
-
revisionHistoryLimit designa el número de versiones de daemonset conservadas.
-
updateStrategy define la estrategia de actualización, como para los Deployment.
Se trata de un componente muy importante en el clúster Kubernetes. Se utiliza para desplegar CNIs (Container Network Interface) o CSIs (Container Storage Interface), por ejemplo. Volveremos a verlo en capítulos posteriores.