
Gestión de datos
Introducción
En los capítulos anteriores, primero hemos estudiado las distintas facetas de los datos y después, cómo almacenarlos, transportarlos y transformarlos en el sistema de información. Por último, hemos aprendido a analizarlos y depurarlos.
Pero los datos también son una materia en movimiento: se desplazan, cambian y evolucionan. Su finalidad es convertirse rápidamente en información y proporcionar así la verdadera riqueza que espera la empresa. Por lo tanto, es esencial establecer normas de gestión de datos para administrar y controlar mejor el ciclo de vida de esta información, que se convertirá en la energía bruta de la empresa.
De la misma manera que en el primer capítulo vimos que los datos son polimorfos y están vivos, con la gestión ocurre lo mismo. La gestión de los datos tiene sus propias reglas. Viene a ser como la ley que los rige y para regularlos es esencial crear una policía de datos. Esto es lo que vamos a estudiar en este capítulo: los recursos y controles que hay que poner en marcha para garantizar la correcta gestión de la información.
Desde el punto de vista de la gestión de datos, debemos distinguir entre varias facetas:
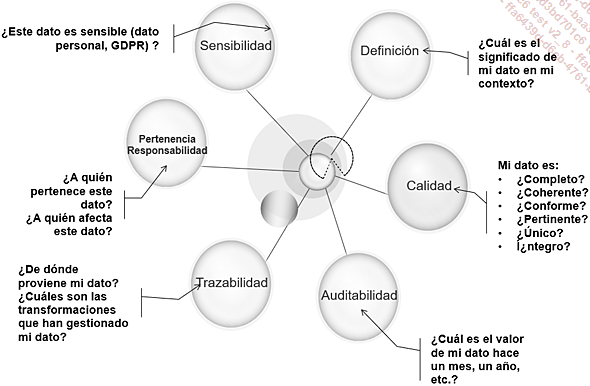
Las facetas de la gestión de datos
A estas facetas hay que añadir las exigencias cada vez más estrictas de los consumidores de datos, como:
-
la exactitud...
El equipo de gestión de datos
Antes de examinar los distintos tipos de herramientas necesarias para llevar a cabo una buena gestión, es esencial describir rápidamente las funciones y misiones de quienes intervienen en ella. Estos roles se describen brevemente a continuación:
-
CDO(Chief Data Officer): no confundir con el Chief Digital Officer. El papel del CDO es impulsar la estrategia de datos de la empresa. Naturalmente, la gestión es una de sus principales preocupaciones, ya que debe garantizar que los datos estén definidos, sean confiables y los usuarios los puedan utilizar en todo momento.
-
Data Steward: de alguna manera, este papel surgió con la gestión de datos. Es una función bastante compleja, porque los Data Steward son empleados que tienen que gestionar y garantizar la integridad de los datos, así como que se recopilan, documentan y su disponibilidad. Es un papel central, porque dicho sea de paso, garantizan la calidad de la información proporcionada. A menudo se plantea la cuestión de las competencias necesarias para desempeñar esta función. Ante todo, estos Data Stewards no son expertos técnicos, pero sí deben al menos tener un conocimiento general de los conceptos, arquitecturas y herramientas técnicas que se utilicen.
-
Data Owner: cada dato y/o metadato debe tener un responsable, de lo contrario ¿cómo acordar un repositorio...
Metadatos
¿Qué son los metadatos? Por definición, un metadato es una información que califica a un dato, aunque hay que reconocer que se trata de una definición un poco vaga. Piense en los metadatos como una forma de definir o incluso describir la información. Recuerde que los datos tienen muchas facetas y que, dependiendo de quién los utilice, pueden tener un significado diferente. Otra finalidad de los metadatos es eliminar ambigüedades sobre lo que realmente contienen los datos. En cierto modo, es una etiqueta esencial que permite calificar, sin lugar a dudas, la información almacenada y gestionada por la empresa. Utilizando de nuevo la metáfora de la etiqueta: los metadatos son a los datos lo que la etiqueta al producto.
Definir la base de metadatos también implica adoptar un doble enfoque, técnico y funcional a la vez. El etiquetado de los datos se puede abordar desde un punto de vista técnico (almacenamiento, nombre de la tabla, nombre de la columna, tipo técnico, etc.), pero también desde un punto de vista semántico y de negocio (número de factura, nomenclatura que se debe respetar, etc.). Por supuesto, el interés en un ámbido de tipo metadatos es conciliar estas dos visiones complementarias de los mismos datos.
1. Los retos de la gestión de metadatos
Por tanto, definir la base de metadatos significa definir el lenguaje común y los recursos tecnológicos de la empresa, lo que también se conoce como catalogación de datos. A menudo, esto significa crear un punto de convergencia entre el propietario del proyecto (PP) y el director del proyecto (DP).
He aquí algunas de las tareas asignadas tradicionalmente a estos dos tipos de perfiles que intervienen en la gestión de datos:
|
Propietario del proyecto (PP) |
Director del proyecto (DP) |
|
VISIÓN FUNCIONAL |
VISIÓN TÉCNICA |
|
Definición de objetivos e indicadores de calidad de los datos Definición de los indicadores de resultados Definición de las unidades de valor Definición de funciones Definición de las normas Definición de procesos Consulta y búsqueda de definiciones de negocio |
Aplicación de normas de control de calidad Aplicación de indicadores de resultados Utilización de unidades de valor Aplicación de funciones: seguridad... |
Linaje de datos
1. Introducción
El linaje de datos (o Data Lineage) es la capacidad de una herramienta o solución para rastrear todas las etapas del movimiento y la transformación de los datos. Imagine que tiene un indicador en uno de sus cuadros de mando y no sabe exactamente de dónde procede esta información. El Data Lineage le permitirá trazar todas las etapas de recuperación de los datos de origen así como las distintas transformaciones que han sido necesarias para producir este indicador. Este tipo de solución puede ser especialmente útil para el análisis de impacto, pero también y, sobre todo, permite comprender mejor los datos en su entorno.
2. Capas de linaje
El linaje de los datos permite comprender no solo de dónde proceden nuestros datos, sino también cómo se utilizan en las distintas aplicaciones y sistemas.
En general, hay dos tipos de metadatos que la solución de linaje necesitará recuperar:
-
La información física: incluye los elementos técnicos del Sistema de Información, como bases de datos, archivos, soluciones, programas, etc. En general, se trata de la base más sólida de nuestro linaje porque sus elementos son fácticos. Incluye:
-
Sistemas (bases de datos, aplicaciones, etc.)
-
DataSets o Tablas, que de hecho son los datos
-
Los campos que componen los DataSets o Tablas
-
El glosario de negocio y la semántica: ya se han tratado anteriormente. A diferencia de la capa física, se puede perfeccionar debido a su subjetividad....
El catálogo de metadatos
La solución que proporciona el catálogo de datos extrae metadatos de diversas fuentes externas (bases de datos, almacén de datos, glosarios corporativos, informes de BI, etc.) para hacerlos accesibles dentro de una interfaz consolidada dedicada a los Data Stewards.
Este tipo de solución le ayuda a analizar y comprender las enormes cantidades de metadatos presentes en los distintos ámbitos de su Sistema de Información. De este modo, es posible:
-
extraer metadatos físicos y operativos de numerosos componentes vinculados a datos,
-
organizar los metadatos en función de conceptos empresariales,
-
mostrar información sobre el linaje y la relación para cada dato
|
El objetivo de este tipo de solución es mantener un catálogo que sirva de repositorio centralizado, y que almacene todos los metadatos de diferentes fuentes externas. |
Muy a menudo, este tipo de solución va acompañada de un motor de descubrimiento que permite recopilar datos desde dentro de la empresa, al mismo tiempo que aumenta su comprensibilidad, gracias a un catálogo precargado de información. De este modo, se facilita enormemente a cualquier tipo de usuario:
-
la búsqueda de todo tipo de datos dentro de la empresa,
-
descubrir las relaciones,
-
enriquecer los datos con un glosario empresarial y anotaciones de usuario,
-
comprender la fuente, la calidad y el uso de sus datos (análisis...
Seguridad de los datos
En los últimos años, la seguridad de los datos se ha convertido en un campo extremadamente prolífico. Hay tanto que decir y que hacer sobre el tema, que podría ser objeto de un libro entero (o más de uno). Por supuesto, el RGPD (Reglamento General de Protección de Datos) ha acelerado muchas iniciativas, lo que finalmente es algomuy positivo, ya que por fin se han sentado las bases de la sensibilidad de los datos y, por supuesto, de las obligaciones en cuanto a gestión y seguridad que tienen quienes los almacenan.
El objetivo aquí no es tratar este tema de forma exhaustiva, sino repasar los principales conceptos en torno a la seguridad de los datos. ¿Cómo proteger los datos almacenados? ¿Cómo hacerlos accesibles y a la vez protegerlos mediante la anonimización, la seudonimización o incluso el cifrado? Estos son los temas que se tratarán en esta sección.
1. Anonimización frente a seudonimización

Extracto del RGPD
En el contexto de la normativa RGPD (o GDPR en inglés), y más concretamente del tema específico de la seguridad de los datos personales, el primer enfoque propuesto (véase el artículo anterior), consiste en seudonimizar los datos personales de forma permanente.
|
Pero, ¿qué es la seudonimización y en qué se diferencia de la anonimización? |
La anonimización y la seudonimización son dos procesos que simplemente alteran los datos para eliminar cualquier connotación personal y hacerlos irreconocibles. En otras palabras, una vez anonimizados o seudonimizados, los datos en su estado actual no deben permitir identificar a una persona.
Sin embargo, hay una diferencia notable entre la anonimización y la seudonimización: la reversibilidad del proceso de alteración. Una vez anonimizados los datos, es imposible establecer el vínculo entre los datos anteriores a la modificación y los generados por el proceso de anonimización. En cambio, tras la seudonimización, los datos se modifican, pero no pierden todo su sentido. Por tanto, existe una especie de residuo de los datos antiguos que persiste y que, combinado con otros datos, puede dar lugar, por ejemplo, a la reversibilidad. Clásicamente, la seudonimización recurre a la criptología (y, por tanto, las claves...
Fábrica de datos (Data Fabric)
Una fábrica de datos (o Data Fabric) es un concepto de arquitectura de datos surgido en la década de 2000 y formalizado por el Instituto Forrester. De hecho, la fábrica de datos es un conjunto de herramientas y prácticas que permiten disponer de datos frescos y de calidad. Las fábricas de datos se basan en el principio de crear un "tejido de datos" coherente que se pueda utilizar directamente por diversos usuarios o consumidores. Sin este modelo, cada unidad de negocio tiene que construir, documentar y gestionar su propio conjunto de datos, lo que en muchos casos tiene sus limitaciones. Además, los tipos de fuentes de datos, los volúmenes y todas las necesidades en términos de datos frescos, aumentan constantemente. Cada vez resulta más complejo y costoso gestionar adecuadamente los activos de datos.
De ahí la idea de aunar todos estos esfuerzos (antes dispersos) reuniéndolos en una única entidad cuya función sería proporcionar datos utilizables. Así nació la fábrica de datos.
Por supuesto, esta fábrica no puede funcionar sin las herramientas adecuadas. Para funcionar, necesita implantar una o varias soluciones que le permitirán:
-
Adquirir datos que le permitan conectarse a cualquier tipo de sistema para recuperar cualquier tipo de datos necesarios;
-
Integrar datos procedentes de varias fuentes heterogéneas...
Mallado de datos (Data Mesh)
Es un hecho que la cantidad de datos aumenta constantemente y de manera proporcional a las necesidades. A pesar de la creación de Data Lake, que siguen creciendo en tamaño y complejidad, asistimos a la proliferación de múltiples islas pequeñas de datos, a veces sin gestionar. Todo esto es complejo de gestionar y controlar y puede convertise rápidamente en un caos. Aunque el enfoque de fábrica de datos puede remediar ciertos problemas y proporcionar una mayor fluidez en el consumo de datos, a medida que los datos y las soluciones se acumulan y se hacen más complejos, también puede quedar rápidamente obsoleta. De ahí la introducción de un nuevo tipo de arquitectura de datos propuesta en 2019 por Zhamak Dehghani.
Este tipo de arquitectura se basa en cuatro pilares:
1. Creación y gestión de un dominio de datos.
2. El principio de los Data as a Product (datos como producto).
3. El principio de Self-Service.
4. Gestión federada.
En pocas palabras...
|
De forma similar a los microservicios, que han permitido segmentar las aplicaciones por dominio en lugar de por tecnología, el Data Mesh (o malla de datos) propone desglosar la gestión de datos por dominio. |
En realidad, la idea subyacente es muy pragmática. Partiendo de la constatación de que es muy complejo hacer coexistir Data Warehouse y Data Lake, y de que las líneas...