
Particiones y sistemas de archivos
Particionar un disco
1. Estructura de un disco duro
a. Introducción a los discos duros y a las particiones
Tipos de disco duro
En este capítulo, se explican los distintos pasos, desde la elección del disco duro hasta la organización de los datos, pasando por la partición, la elección de un sistema de archivos y el formateo.
Existen varias tecnologías de discos duros, algunas más orientadas a las empresas que otras:
-
IDE (Integrated Drive Electronics): orientado al consumidor, ahora obsoleto, sustituido por SATA.
-
SCSI (Small Computer System Interface): caro, pero con un rendimiento adaptado a las necesidades de la empresa.
-
SATA (Serial ATA): sucesor de IDE, económico y bastante potente, aunque este tipo de unidad está más bien pensado para un uso doméstico.
-
SAS (Serial Attached SCSI): combina las ventajas de SCSI y SATA.
-
SSD (Solid State Drive): este outsider (desconocido) no es, estrictamente hablando, una tecnología de disco duro, pero tiene las mismas características. Utiliza memoria flash y su rendimiento es ahora mejor que el de los discos duros tradicionales. Su precio ha bajado considerablemente, lo que lo convierte en la opción preferida en los centros de datos (datacenters).
Elección del disco duro
Los discos duros SCSI han reinado durante mucho tiempo en la empresa gracias a su rendimiento.
Por ejemplo, los discos SCSI giran a velocidades de entre 10 000 y 15 000 rpm, lo que reduce los tiempos de acceso y transferencia. Sin embargo, los discos duros SATA están ya muy consolidados en el mercado empresarial, a pesar de que sus velocidades de rotación son inferiores (de 7 200 a 10 000 rpm). Se necesitan comparar otros criterios además de la velocidad de rotación, como el precio, la velocidad de transferencia y el tipo de uso, que pueden adaptarse a sus necesidades. Además, las unidades SATA de clase empresarial son cada vez más fiables: su MTBF (Mean Time Between Failure, tiempo medio entre fallos) es cada vez mayor.
SAS ha resuelto este dilema. Esta tecnología es el resultado del deseo de los principales fabricantes de combinar las ventajas de SCSI y SATA. Se considera la sucesora de SCSI. Con SAS, obtendrá discos duros fiables y de alto rendimiento.
En resumen, SAS es la solución fiable y de alto rendimiento, que compite con SATA, que es menos cara....
LVM (Logical Volume Manager, Gestor de volúmenes lógicos)
1. Presentación
LVM (Logical Volume Manager, Gestor de Volúmenes Lógicos) satisface una necesidad de flexibilidad en el particionado que ha surgido con el tiempo.
Es cierto que el sistema de partición clásico intentó evolucionar con las necesidades. Las particiones lógicas dentro de una partición extendida permitieron ampliar el número de particiones. También se ha hecho posible redimensionar una partición, pero esta operación, a veces arriesgada, requiere mucho tiempo y no puede realizarse «en caliente» (cuando el sistema de archivos está en uso).
LVM es, como su nombre indica, un tipo de gestión de volúmenes lógicos, lo que significa que ya no se opera directamente sobre las particiones físicas del disco duro. En su lugar, se añade una capa de software intermedia entre el disco duro y el sistema operativo, cuyo manejo es mucho más flexible.
Cómo funciona
LVM funciona agrupando discos duros y particiones físicas en un gran «grupo común» (pool), que luego se redistribuye en forma de nuevas particiones, esta vez lógicas en lugar de físicas.
-
Los discos duros y las particiones físicas se denominan volúmenes físicos (PV, physical volumes).
-
Este depósito común en el que se reúnen se denomina grupos de volúmenes (VG, Volume groups).
-
La redivisión de esta base común en particiones lógicas se denomina volúmenes lógicos (LV, Logical volumes).
Una vez que entienda la lógica que hay detrás de LVM, la gestión es relativamente sencilla, ya que los comandos son muy directos.
Volúmenes físicos
En inglés, Physical Volumes (PV) puede ser:
-
un disco entero (no recomendado),
-
particiones de un disco creado con parted, primarias o lógicas,
-
particiones o discos duros en un volumen RAID físico (esto es transparente para LVM),
-
un volumen iSCSI o Fibre Channel que el sistema considera como una partición.
Esto hace posible distribuir sus datos en varias particiones, discos duros e incluso a través de la red.
Grupos de volúmenes
Los Grupos de volúmenes (VG) son concatenaciones de volúmenes físicos (PV).
Volúmenes lógicos
Los grupos...
Stratis
Stratis, cuya promoción está siendo relativamente discreta, es una herramienta desarrollada por Red Hat e integrada desde su versión 8.
Stratis es una herramienta de gestión y control del almacenamiento diseñada para unificar las tecnologías de almacenamiento de alto rendimiento existentes y ofrecerlas en una única interfaz desarrollada en el espacio del usuario (User Space). Esta técnica permite sacar a la luz funciones de bajo nivel que antes estaban reservadas al núcleo, lo que facilita el desarrollo de nuevas funciones sin tener que recompilar el núcleo.
Stratis reúne en una única interfaz los conceptos relativos a LVM y XFS, así como a BTRFS, que ya no está disponible en RHEL 8.8. En la siguiente demostración, encontrará conceptos familiares de LVM como:
-
blockdev: equivalente al volumen físico (LVM), las particiones y los discos duros que participan en el pool.
-
pool: equivalente a un grupo de volúmenes (LVM), agrupa los blockdev en depósitos de bloques de datos, a partir de los cuales se crean los sistemas de archivos.
-
filesystem: equivalente al volumen lógico (LVM), es la partición lógica final que montaremos en nuestra arborescencia. Tenga en cuenta que Stratis ya crea el sistema de archivos, a diferencia de LVM, que requiere el uso de mkfs una vez creado el volumen lógico.
La creación de un sistema de archivos con Stratis es idéntica a la creación de un volumen lógico en LVM.
1. Crear un sistema de archivos
En primer lugar, hay que instalar e iniciar Stratis, si aún no lo ha hecho:
dnf install stratisd stratis-cli
systemctl enable --now stratisd 1) Declarar blockdevs y crear un pool
stratis pool create <nombre del pool> </dev/disco> </dev/disco> Se puede añadir un blockdev a un pool existente:
stratis pool add-data <nombre del pool> </dev/disk> Tenga en cuenta que el blockdev puede ser un LV LVM.
2) Crear un sistema de archivos
stratis filesystem create <nombre...RAID
1. Presentación
a. ¿Qué es RAID?
RAID es el acrónimo de Redundant Array of Independent Disks (o matriz redundante de discos independientes), que intenta describir mejor la técnica de distribución de datos entre varios discos para aumentar la fiabilidad, la tolerancia a fallos o el rendimiento.
b. Niveles de RAID
RAID 0: volumen dividido
El objetivo del RAID 0 no es proporcionar fiabilidad, sino rendimiento. Esta configuración permite que varios discos trabajen en paralelo.
Los datos se distribuyen en bandas entre todos los discos. Esto permite acceder a varios datos al mismo tiempo, lo que reduce significativamente los tiempos de acceso.
Sin embargo, si uno de los discos falla, se pierde todo el volumen.
RAID 1: en espejo
Esta configuración está diseñada para proporcionar la máxima fiabilidad, escribiendo los mismos datos en dos o más discos al mismo tiempo. Los discos son réplicas unos de otros.
Dependiendo de la configuración, aunque fallen varios discos, los datos seguirán estando presentes y accesibles mientras haya un disco válido.
Por supuesto, el espacio disponible se reduce. Para un RAID 1 de dos discos, solo se utiliza el 50% del espacio total del disco.
Esta configuración no ofrece ninguna mejora de rendimiento.
RAID 5: distribuido con paridad
El RAID 5 pretende una solución intermedia entre el RAID 1 y una mayor eficiencia del espacio en disco, utilizando las matemáticas.
Esta tecnología utiliza la paridad para reconstruir los bloques de datos perdidos. Los bloques de datos y los de paridad se distribuyen entre todos los discos (3 como mínimo).
Si uno de los discos falla, los otros discos (que contienen los bloques de paridad y los demás bloques de datos) pueden utilizarse para reconstruir los datos que faltan.
El espacio total es, por tanto, más rentable que con el RAID 1, para una solución relativamente fiable. Por ejemplo, para un volumen RAID 5 con tres discos (es el mínimo), se puede utilizar el 66% del espacio total.
La desventaja de esta solución es el tiempo que se tarda en reconstruir los datos perdidos, que puede ser bastante largo, de hasta varias horas, una vez sustituida la unidad averiada. Esto puede ser un inconveniente si otra unidad falla al mismo tiempo.
Es más, RAID 5 puede ser una fuente de problemas...
Instalar un sistema de archivos
1. Presentación
Un sistema de archivos describe la forma en que se almacenan y organizan los datos en cualquier medio de almacenamiento, como el almacenamiento masivo (disco duro, CD-ROM o memoria USB) o la red.
Es necesario describir con precisión cómo se almacenan los datos en el soporte físico: cómo se indexan los archivos y directorios, cómo se pueden abrir, borrar o copiar y cómo se puede acceder a ellos.
El sistema de archivos también proporciona al usuario una representación de los datos, relativamente independiente de la estructura física de los mismos. La mayoría de las veces, el usuario verá los archivos como una arborescencia, que contiene archivos y subdirectorios.
Existen varias filosofías más o menos estándar para organizar los datos. Por lo general, dependen de los sistemas operativos para los que se crearon los sistemas de archivos. En general, pueden dividirse en las siguientes categorías:
-
sistemas de archivos sin bitácora,
-
sistema de archivos en red,
-
sistema de archivos agrupado o en clúster,
-
Existen, por supuesto, muchos otros tipos de sistemas de archivos, dedicados a aplicaciones muy específicas. Entre ellos, se encuentran los sistemas de archivos criptográficos, los sistemas de archivos virtuales y los pseudosistemas de archivos.
Por extensión, el sistema de archivos también describe la partición formateada en un tipo concreto de sistema de archivos.
Por ejemplo, operaciones como montar un sistema de archivos o comprobar un sistema de archivos.
Sistemas de archivos sin bitácora
Los sistemas de archivos sin bitácora son muy variados y la organización de los datos difiere de un sistema a otro. Sin embargo, todos entran en la misma categoría porque tienen algo en común: sus limitaciones hacen que no se adapten a los soportes de almacenamiento actuales, que son cada vez más grandes y exigen un mayor rendimiento.
Los dos principales sistemas de archivos sin bitácora que nos interesan para su uso en un servidor Red Hat Enterprise Linux son:
-
FAT y todos sus derivados, por compatibilidad con el mundo Windows;
-
ext2, el abuelo del actual sistema de archivos utilizado en Red Hat Enterprise Linux, ext4.
El sistema de archivos FAT utiliza una tabla de asignación de archivos (File Allocation Table, FAT), que es una especie de mapa que refleja la organización y el estado de los archivos en el disco. Para acceder a un archivo, primero hay que acceder a FAT, que indica dónde se encuentran los datos en el disco. A veces, hay que navegar por todo el FAT, lo que puede degradar el rendimiento si se almacenan archivos de gran tamaño en particiones muy grandes.
En cuanto a ext2, su organización es similar a la de ext3/ext4, sin bitácora. Desarrollamos la filosofía de los inodos en la sección Estructura de datos en Linux.
La principal desventaja de los sistemas de archivos sin bitácora surge cuando el sistema se apaga repentinamente. Cuando se reinicia el sistema, se necesita comprobar la integridad de los datos explorando todo el sistema de archivos, lo que puede llevar mucho tiempo en el caso de soportes de gran tamaño. Por ejemplo, si se borra un archivo o se realiza una copia, no se guarda ningún rastro de estas acciones y es necesario comprobar la coherencia de los datos.
Sistemas de archivos con bitácora
Los sistemas de archivos con bitácora tienen diferentes formas de organizar los datos, pero lo que tienen en común es el principio del registro diario, que permite que el soporte vuelva a su estado normal muy rápidamente tras una parada repentina.
Cada operación se anota en un registro, de modo que se conserva un rastro de las acciones. El sistema es consciente en todo momento de las acciones completadas o en curso. En caso de apagado repentino del sistema, solo es cuestión de consultar el registro y comprobar si se ha completado o no la última acción en curso. Esto lleva infinitamente menos tiempo que en un sistema de archivos sin bitácora.
Los sistemas de archivos con bitácora más comunes son:
-
ext4: Este es el sistema de archivos predeterminado utilizado en Red Hat Enterprise Linux hasta la versión 6.
-
NTFS: es el sistema de archivos utilizado por los sistemas operativos de Microsoft desde Windows NT. Linux puede utilizar este sistema de archivos.
-
XFS: un sistema de archivos de alto rendimiento, capaz de soportar altas tasas de bits y archivos de gran tamaño. Es el sistema de archivos predeterminado a partir de RHEL 7.
Sistemas de archivos en red
El principio de los sistemas de archivos de red es acceder a los datos almacenados en otra máquina a través de la red. Obviamente, el acceso a los datos no se define de la misma manera que el acceso a un medio de almacenamiento local.
Existen dos tecnologías principales para los sistemas de archivos en red:
-
SMB/CIFS: protocolo de intercambio de archivos de Microsoft, soportado en Linux por el software Samba.
-
NFS: el protocolo de compartición de archivos nativo de los servidores Unix/Linux.
Sistema de archivos agrupados
Los sistemas de archivos agrupados (clúster) permiten repartir una partición entre varias máquinas. Esto es adecuado para un entorno de clúster, en el que varias máquinas realizan una tarea conjuntamente.
En Red Hat Enterprise Linux, el tipo de sistema de archivos agrupados elegido es GFS (Global File System, sistema de archivos global).
Metadatos
Detrás de este nombre bárbaro se esconde un principio sencillo: los metadatos son datos que apuntan a otros datos. Es necesario conservar información sobre los archivos y directorios almacenados en el soporte.
En Unix/Linux, los metadatos más comunes son:
-
derechos de acceso,
-
usuario y grupo propietarios,
-
tamaño,
-
fecha de acceso, cambio y modificación del archivo,
-
tipo de archivo (archivo estándar, enlace simbólico, directorio, dispositivo, etc.),
-
número de enlaces físicos y simbólicos,
-
atributos extendidos y listas de control de acceso,
-
direcciones de bloques de datos.
Curiosamente, ¡la fecha de creación de un archivo no se almacena en ninguna parte!
Aunque existen otros metadatos, los datos descritos aquí se almacenan en el inodo, que explicamos a continuación.
2. Estructura de datos en Linux
a. Extended File System (Sistema de archivos extendido)
Extended File System, más comúnmente conocido como ext, fue el primer sistema de archivos creado específicamente para Linux. De hecho, los principales conceptos que aún se utilizan hoy en día se implementaron completamente en la versión 2 de ext (ext2), que es el antepasado de las versiones ext3 y ext4 utilizadas en los servidores Red Hat Enterprise Linux. Con el tiempo, aparecieron otros tipos de sistemas de archivos, como XFS, que también utiliza Red Hat.
Virtual File System (Sistema de archivos virtual)
La demanda de unificación de los tipos de sistemas de archivos llevó a la creación del Virtual File System, que es una capa intermedia entre los sistemas de archivos heterogéneos y la estructura de la arborescencia. Proporciona al usuario una visión unificada, aunque se utilicen diferentes sistemas de archivos. De este modo, permite generalizar conceptos específicos de los sistemas de archivos ext a sistemas de archivos que no los implementan, como NTFS. En este caso, VFS realiza una conversión.
Los conceptos específicos de Linux que vamos a explorar ahora se implementan físicamente en el sistema de archivos o virtualmente mediante VFS.
En el corazón de la familia de sistemas de archivos ext utilizada en Linux, se encuentra la noción de inodo, que es uno de los conceptos fundamentales que se debe comprender para entender la estructura de los sistemas de archivos Linux.
b. El superbloque
El superbloque (superbloc) contiene información general sobre el sistema de archivos. La información relevante incluye:
-
Número de montajes: este concepto se explica en la sección Montar el sistema de archivos.
-
Inodos disponibles.
-
Bloques de datos disponibles.
-
Primer inodo: esta información es necesaria para entender cómo funciona el sistema de archivos ext. El primer inodo contiene el número de inodo del directorio raíz (denominado /) del sistema de archivos.
Como el superbloque contiene información vital para el sistema de archivos, se sitúa al principio del sistema de archivos y se repite a intervalos regulares.
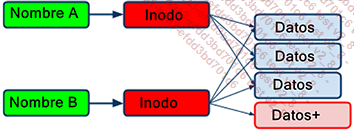
c. Inodos
Los inodos son estructuras de datos, o «cajas», que almacenan los metadatos de los archivos. Sin embargo, no contienen los nombres de los archivos.
Cuando un usuario quiere acceder a un archivo, el sistema accede primero a su inodo y lee sus metadatos. Entre otras cosas, comprueba los permisos para determinar si el usuario tiene derecho a leer, modificar o ejecutar los datos.
En función de los permisos, el sistema también determina la dirección de los datos (su ubicación en el sistema de archivos). Por último, puede acceder a los datos propiamente dichos, que se encuentran en la dirección indicada en el disco duro.
Los directorios también son archivos referenciados por inodos. Listar su contenido significa, por tanto, seguir el mismo procedimiento: consultar el inodo del directorio y, a continuación, acceder a sus datos, que son de hecho la lista de archivos contenidos en el directorio con su correspondiente número de inodo.
d. Tabla de inodos
La tabla de inodos de un sistema de archivos contiene los inodos asignados al sistema de archivos.
En general, el número de inodos se define cuando se crea el sistema de archivos (excepto en ciertos casos, como con XFS), cuando formatea la partición. Dado que un archivo corresponde generalmente a un inodo, esto significa que el número de archivos es limitado en un sistema de archivos ext2/3/4.
Para conocer el número total de inodos de un sistema de archivos montado en la arborescencia, así como el número de inodos disponibles, utilice el comando:
df -i Por ejemplo:
[root@cobb ~]# df -i
S.archivos Nodos-i Nusados NLibres NUso% Montado en
/dev/sda1 1150560 96204 1054356 9% / Podemos ver que para la partición /dev/sda1, se asignaron 1 150 560 inodos cuando se creó el sistema de archivos.
Para un sistema de archivos formateado, pero no montado aún, el comando tune2fs también proporciona el número total y disponible de inodos, así como otra información muy interesante (opción -l de list, listar):
tune2fs -l /dev/<partición> Por ejemplo, la partición /dev/sde1 no se ha montado aún:
[root@cobb ~]# tune2fs -l /dev/sde1
tune2fs 1.41.12 (17-May-2010)
Filesystem volume name: <none>
Last mounted on: <not available>
Filesystem UUID: f390de17-7655-4990-b768-a5fba7b5e170
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode
dir_index filetype sparse_super
Filesystem flags: signed_directory_hash
Default mount options: (none)
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 28112
Block count: 112420
Reserved block count: 5621
Free blocks: 103202
Free inodes: 28101
First block: 1
Block size: 1024
(...) Esta partición contiene un total de 28 112 inodos, 28 101 de los cuales están disponibles.
e. Tabla de bloques
La tabla de bloques contiene los bloques de datos de los archivos, es decir, el contenido real de los archivos.
También en este caso, el número de bloques disponibles se define cuando se crea el sistema de archivos (cuando se formatea la partición). Cada bloque tiene un tamaño fijo.
En el ejemplo anterior, podemos ver que la partición /dev/sde1 tiene un total de 112 420 bloques de datos. Cada bloque tiene un tamaño de 1 024 bytes. Cuando se formatea, algunos bloques de datos son utilizados por el sistema, dejando 103 202 bloques de datos que proporcionan alrededor de 105 678 KB de espacio disponible (103 202 bloques x 1 024 bytes/bloque), es decir, alrededor de 105 MB.
f. Ilustración de la estructura del sistema de archivos
Ilustremos cómo funciona el sistema de archivos ext trazando los diferentes pasos de acceso a un archivo.
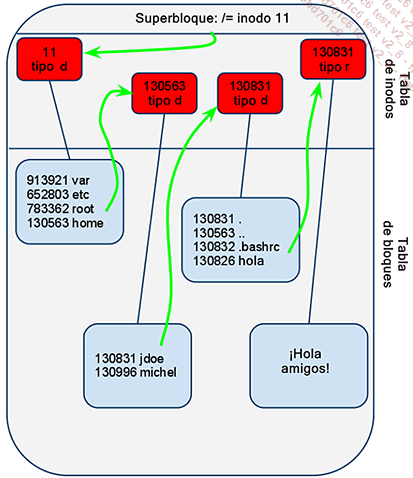
Estructura del sistema de archivos
Cuando el usuario jdoe teclea el comando:
cat /home/jdoe/hola 1. El sistema operativo comienza leyendo el número del primer inodo correspondiente a la raíz / en el superbloque. Aquí, el primer inodo tiene el número 11.
[root@cobb jdoe]# debugfs /dev/sda2
debugfs: stats
Filesystem volume name: <none>
Last mounted on: /
(...)
First inode: 11 2. El sistema accede entonces al inodo 11, comprueba los permisos de acceso para este directorio y busca la dirección del bloque de datos, aquí: 9217
debugfs: show_inode_info /
Inode: 2 Type: directory Mode: 0555 Flags: 0x0
(...)
BLOCKS:
(0):9217 3. El sistema abre el bloque de datos 9217 que contiene las listas de directorios y archivos contenidos en /. Encuentra una coincidencia entre los nombres y los números de inodo:
783361 dev 261121 proc 391681 sys
913921 var 652801 tmp 652803 etc
783362 root 130562 selinux 391685 srv
130618 misc 261122 usr 391682 bin
130563 home 783365 lib 391683 media
130564 mnt 391684 opt 130565 sbin 4. El sistema accede al inodo 130563 correspondiente al directorio /home, comprueba los permisos de acceso a este directorio y busca la dirección del bloque de datos: 532482.
debugfs: show_inode_info /home
Inode: 130563 Type: directory Mode: 0755 Flags: 0x80000
(...)
BLOCKS:
(0): 532482 5. El sistema abre el bloque de datos 532482 que contiene las listas de directorios y archivos contenidos en /home. Encuentra la correspondencia entre el nombre jdoe y su número de inodo:
debugfs: ls /home
130563 . 2 .. 130831 jdoe
130996 michel 130994 admin 131009 ITprojets 6. El sistema accede al inodo 130831 correspondiente al directorio jdoe, comprueba los permisos de acceso a este directorio y busca la dirección del bloque de datos: 532492.
debugfs: show_inode_info /home/jdoe
Inode: 130831 Type: directory Mode: 0700 Flags: 0x80000
(...)
BLOCKS:
(0): 532492 7. El sistema abre el bloque de datos 532492 que contiene las listas de directorios y archivos contenidos en jdoe. Encuentra una correspondencia entre los nombres y los números de inodos:
debugfs: ls /home/jdoe
130831 . 130563 .. 130832 .bashrc
(...) 130826 hola 8. El sistema accede al inodo 130826 correspondiente al archivo hola, comprueba los permisos de acceso a este archivo y busca la dirección del bloque de datos. Los permisos son los siguientes: el usuario propietario tiene UID 500, el grupo propietario tiene GID 500 y los derechos de acceso son 0664. Los datos de este archivo se almacenan en el bloque 3707450.
debugfs: show_inode_info /home/jdoe/hola
Inode: 130826 Type: regular Mode: 0664 Flags: 0x80000
Generation: 4191462316 Version: 0x00000000:00000001
User: 500 Group: 500 Size: 19
(...)
BLOCKS:
(0): 3707450 9. Finalmente, como el sistema se da cuenta de que el tipo de archivo es regular, accede a los datos del bloque 3707450 y los pasa al comando cat, que muestra su contenido:
[jdoe@cobb ~]$ cat /home/jdoe/hola
¡Hola, amigos! g. Vínculos simbólicos y físicos
Hemos optado por explicar aquí los vínculos, ya que utilizan conceptos directamente relacionados con la estructura del sistema de archivos.
Los vínculos (también llamados enlaces) son archivos utilizados como accesos directos a otros archivos (o directorios).
Existen dos tipos de vínculos: físicos y simbólicos.
Vínculos simbólicos
Los vínculos simbólicos (o symlinks) son los más sencillos de entender. Son entradas en directorios, como los archivos regulares. Sin embargo, a diferencia de los archivos regulares, en lugar de apuntar a un número de inodo, un vínculo simbólico apunta al nombre de otro archivo. Se puede pensar en ellos como alias de archivos, no muy diferentes de los accesos directos utilizados en Windows.
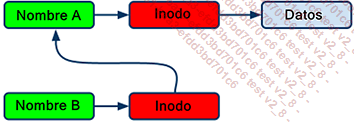
Diagrama explicativo del vínculo simbólico
Por ejemplo, en /etc/rc5.d/, encontramos vínculos simbólicos:
[root@cobb rc5.d]# ls -l
lrwxrwxrwx. 1 root root K01certmonger -> ../init.d/certmonger
lrwxrwxrwx. 1 root root K01smartd -> ../init.d/smartd
lrwxrwxrwx. 1 root root K02oddjobd -> ../init.d/oddjobd
lrwxrwxrwx. 1 root root K10psacct -> ../init.d/psacct Aquí vemos que el archivo K01smartd apunta al archivo normal smartd en el directorio init.d.
Así, cuando se llama a /etc/rc5.d/K01smartd, se abre /etc/init.d/smartd.
Lo que necesita saber sobre los vínculos simbólicos
-
En el resultado del comando ls -1, el tipo de archivo de un vínculo simbólico es l (link).
-
Un vínculo simbólico puede apuntar a un archivo o directorio normal, precedido de una ruta relativa o absoluta.
-
Un vínculo simbólico tiene su propio número de inodo, distinto del archivo al que apunta.
-
La acción de mostrar el archivo apuntado en lugar del vínculo simbólico se denomina desreferenciar.
-
Los vínculos simbólicos se utilizan en muchos lugares de la arborescencia de su servidor. Aprenda a encontrarlos utilizando el comando ls -1h . También puede utilizarlos para facilitar la gestión de su servidor.
Vínculos físicos
Los vínculos físicos (hardlinks) aputan a los datos físicos de otro archivo. En concreto, un enlace físico apunta al mismo inodo que el archivo original.
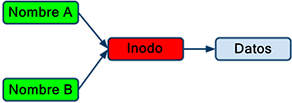
Diagrama explicativo del vínculo físico
Sabemos por las explicaciones anteriores que un archivo se compone de tres elementos:
-
un nombre, o una etiqueta en un directorio, que apunta a un inodo,
-
un inodo, que contiene metadatos y apunta a los datos,
-
los datos.
Cuando crea un vínculo físico, en realidad está creando una nueva entrada en un directorio, apuntando al mismo inodo. Así que cualquier archivo normal es en sí mismo un vínculo físico. Otro enlace físico se encuentra en el mismo nivel que el primer vínculo físico.
Lo que necesita saber sobre los vínculos físicos
-
Todos los vínculos físicos hacia el mismo archivo tienen el mismo número de inodo.
-
Eliminar uno de los vínculos físicos no borra los datos mientras siga existiendo una referencia a ellos (otro enlace físico). Por lo tanto, el sistema debe llevar un registro del número de vínculos físicos que acceden a los datos. Este es el número que puede verse en el resultado del comando ls -l, justo antes de la columna de usuario propietario.
Por ejemplo, el comando ls -il muestra los detalles de los archivos con su número de inodo (opción -i).
[root@cobb ~]# ls -il
799111 -rw-r--r--. 2 root root 19 12 ene 12:54 archivo
799111 -rw-r--r--. 2 root root 19 12 ene 12:54 mismoarchivo Los dos archivos tienen el mismo número de inodo (799111). Son vínculos físicos, que apuntan a los mismos datos (concretamente, al mismo inodo).
Observe el número 2 para cada nombre de archivo, en la tercera columna. Este es el número de enlaces físicos de un archivo.
Eliminemos uno de los vínculos físicos y volvamos a observar esta cifra: ha disminuido a 1.
[root@cobb ~]# rm -f archivo
[root@cobb ~]# ls -il
799111 -rw-r--r--. 1 root 19 12 ene 12:54 mismoarchivo Diferencia entre vínculos simbólicos y físicos
La diferencia entre un vínculo simbólico y uno físico radica principalmente en que un vínculo simbólico depende del archivo al que apunta.
Si ya no existe, el vínculo simbólico está roto e inutilizable.
El vínculo físico no depende del archivo al que se apunta. De hecho, está al mismo nivel que el archivo original: accede directamente a los datos. De hecho, cada archivo es un enlace físico, que accede a los datos.
En el caso en que dos vínculos físicos hagan referencia a los mismos datos, si el primero de ellos, el «primer» archivo, desaparece, el segundo enlace físico sigue accediendo a los datos.
Creación de vínculos físicos o simbólicos
Para crear un vínculo (simbólico o físico), utilice el comando ln.
Vínculo físico:
ln <archivo_original> <nuevo_archivo> Vínculo simbólico (opción -s):
ln -s <archivo_apuntado> <nuevo_archivo> En el caso de un vínculo simbólico, tenga en cuenta los siguientes puntos a la hora de especificar la ruta (relativa o absoluta) del archivo al que se apunta:
-
Ruta relativa: si se mueve el archivo al que se apunta o el enlace simbólico, el vínculo se rompe, pero si se mueven ambos a la vez, manteniendo la misma distancia relativa, el enlace se conserva.
-
Ruta absoluta: si el archivo apuntado se mueve, el vínculo se rompe. El enlace simbólico puede moverse sin consecuencias.
Los vínculos simbólicos no siempre son fáciles de manejar. Experimente para familiarizarse con el concepto.
Copy-on-Write o almacenamiento optimizado (XFS)
Copy-on-Write (COW o CoW copiar al escribir) optimiza la forma en que se almacenan los datos redundantes en el sistema de archivos. Cuando dos archivos comparten datos, en lugar de escribirlos dos veces, es posible compartirlos. Los archivos acceden entonces a los mismos bloques de datos, que solo se escriben una vez.
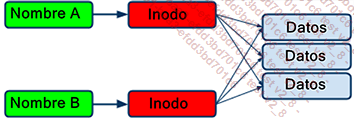
Copy-on-Write: dos archivos comparten los mismos bloques de datos
Solo cuando se añaden datos a uno de los dos archivos comienza a consumirse espacio en disco. Los bloques de datos comunes siguen compartiéndose siempre que sea posible.
Copy-on-Write: añadir datos a uno de los dos archivos
El COW tiene las tres siguientes ventajas:
-
Velocidad: cuando se realiza una copia, los bloques de datos no se duplican. Solo se escriben los metadatos (nombre de archivo, inodo). Por tanto, la copia es instantánea, incluso para archivos de gran tamaño.
-
Optimización del espacio en disco: el archivo copiado de forma idéntica no consume espacio. Este método ya se utiliza en las bahías de almacenamiento SAN (Storage Area Network, red de área de almacenamiento), donde pueden almacenarse miles de millones de archivos, algunos con bloques de datos idénticos, bajo el término deduplicación de datos.
-
Transparencia: Los archivos COW tienen las mismas propiedades que los archivos estándar.
La función COW está activada de forma predeterminada en XFS. Puede comprobarlo con el comando xfs_info <punto de montaje>.
La función COW solo está disponible en el sistema de archivos XFS (y BTRFS, descontinuado a partir de RHEL 8), donde se denomina reflink.
Por defecto, COW no se utiliza al copiar archivos.
Para realizar una copia de archivo con COW, utilice la opción --reflink:
cp --reflink <fuente> <destino> En nuestro ejemplo, tenemos un archivo de 2 GB llamado test2G (que contiene datos aleatorios generados con el comando dd):
[root@scott democow]# dd if=/dev/urandom of=test2G bs=1M count=2048
2048+0 registros leídos
2048+0 registros escritos
2147483648 bytes (2,1 GB, 2,0 GiB) copiados, 98,0044 s, 21,9 MB/s
[root@scott democow]# ls -lh
total 4,0G
-rw-r--r--. 1 root root 2,0G 17 sep 05:13 test2G
[root@scott democow]# df -hP /
S.archivos Tamaño Usados Disp Uso% Montado en
/dev/mapper/rhel-root 17G 6,0G 11,1G 47% / Hagamos una copia clásica del archivo test2G a test2G_cp_classique (cronometrada con el comando time). Vemos que la copia lleva cierto tiempo: se necesitan 58 segundos para duplicar los bloques de datos en este nuevo archivo, que ahora ocupa 2 GB más de espacio en disco (comando df):
[root@scott democow]# time cp test2G test2G_cp_clasico
real 0m58,731s
user 0m0,020s
sys 0m7,293s
[root@scott democow]# ls -lh
total 4,0G
-rw-r--r--. 1 root root 2,0G 17 sep 05:13 test2G
-rw-r--r--. 1 root root 2,0G 17 sep 05:15 test2G_cp_clasico
[root@scott democow]# df -hP /
S.archivos Tamaño Usados Disp Uso% Montado en
/dev/mapper/rhel-root 17G 8,0G 9,1G 47% / Hagamos ahora una copia COW utilizando la opción --reflink, a un nuevo archivo llamado test2G_cp_reflink_CoW. ¿Cuánto tarda la copia? Podemos ver que es casi instantánea:
[root@scott democow]# time cp --reflink test2G test2G_cp_reflink_CoW
real 0m0,006s
user 0m0,001s
sys 0m0,004s
[root@scott democow]# ls -lh
total 6,0G
-rw-r--r--. 1 root root 2,0G 17 sep 05:13 test2G
-rw-r--r--. 1 root root 2,0G 17 sep 05:15 test2G_cp_classique
-rw-r--r--. 1 root root 2,0G 17 sep 05:17 test2G_cp_reflink_CoW También podemos ver que esta copia en COW no utiliza ningún espacio extra en disco; el espacio utilizado es el mismo que antes de la copia:
[root@scott democow]# df -hP /
S.archivos Tamaño Usados Disp Uso% Montado en
/dev/mapper/rhel-root 17G 8,0G 9,1G 47% / ¿Cómo se hace esto? El comando xfs_bmap nos permite ver las direcciones de los bloques de datos utilizados por los archivos:
[root@scott democow]# xfs_bmap -v test2G test2G_cp_reflink_CoW
test2G_cp_classique
test2G:
EXT: FILE-OFFSET BLOCK-RANGE AG AG-OFFSET TOTAL
0: [0..4194303]: 20562136..24756439 3 (1687768..5882071) 4194304
100000
test2G_cp_reflink_CoW:
EXT: FILE-OFFSET BLOCK-RANGE AG AG-OFFSET TOTAL
0: [0..4194303]: 20562136..24756439 3 (1687768..5882071) 4194304
100000
test2G_cp_classique:
EXT: FILE-OFFSET BLOCK-RANGE AG AG-OFFSET TOTAL
0: [0..130943]: 24756440..24887383 3 (5882072..6013015)
130944
1: [130944..2097023]: 2775224..4741303 0 (2775224..4741303)
1966080
2: [2097024..4194303]: 7997128..10094407 1 (1705672..3802951)
2097280 Podemos ver aquí que el archivo copiado en COW utiliza exactamente los mismos bloques de datos que el archivo original, lo que no ocurre con el archivo copiado de forma convencional, que utiliza sus propios bloques.
h. Fragmentación
La gestión de la fragmentación en los sistemas de archivos ext es bastante elegante. En lugar de colocarlos de extremo a extremo en un intento de «apretarlos al principio» como ocurre con otros sistemas de archivos, ext reparte los archivos por toda la partición.
Los archivos están «aireados», con espacio entre ellos. De este modo, un archivo puede crecer libremente ocupando los siguientes bloques de datos libres. Esto limita enormemente la fragmentación, siempre que su sistema de archivos tenga una tasa de ocupación bastante baja: hay que mantener espacio entre los archivos.
i. Descriptores de archivos (File...
Montar el sistema de archivos
Montar un sistema de archivos consiste en dar existencia en la arborescencia al sistema de archivos que acaba de crear. Mientras que, en algunos sistemas operativos, como Windows, este paso es transparente, en un servidor Red Hat Enterprise Linux debe realizarlo el gestor.
La razón principal es que, en Linux, el gestor tiene que tomar ciertas decisiones. El diseño de la arborescencia en los sistemas Linux significa que su nueva partición estará completamente integrada y, por tanto, será transparente: un usuario sin experiencia (ni un software) no podrá saber si un directorio está en el disco local o en otro disco.
Montar un sistema consiste en elegir un punto de acceso a este sistema de archivos en la arborescencia.
Esto se hace definiendo un directorio para acceder a este nuevo sistema de archivos. Al entrar en este directorio, se accede a los archivos de la partición en cuestión.
Este directorio de acceso se denomina punto de montaje.
Por ejemplo, acaba de crear la partición /dev/sdb1. Ahora necesita declarar su existencia en la arborescencia. Cree un directorio /database y asócielo a su nuevo sistema de archivos.
Cuando entra en el directorio /database/, en realidad está accediendo a los archivos de la partición /dev/sdb1.
La ventaja de este mecanismo es que la implementación de un nuevo sistema de archivos es transparente para el sistema operativo y para los programas que utilizan el disco. Esto significa menos trabajo de configuración para usted.
Por ejemplo, suponga que el directorio /home que contiene los archivos de usuario está en el disco principal, junto con el resto de la arborescencia. Ahora decide que los archivos de usuario estarán en una partición separada.
Mueva todos los archivos de usuario a esta nueva partición. A continuación, monte la partición en el directorio /home. A partir de ese momento, cuando los usuarios entren en su directorio, accederán a una partición separada (pero no se darán cuenta).
Vamos a explicar cómo montar un sistema de archivos manualmente y cómo configurar el montaje automático de este sistema de archivos al arrancar la máquina.
1. Información necesaria antes de la instalación
a. Conocer el tipo de sistema de archivos de una partición
Para montar una partición, necesita...
Espacio de intercambio (Swap)
El espacio de intercambio es una partición formateada en un tipo específico de sistema de archivos. En Linux, el espacio de intercambio también puede ser un archivo, al igual que en Windows. Este método se utiliza cada vez más, aunque por el momento es la partición Swap la recomendada por Red Hat.
¿Qué tamaño darle a la partición Swap?
Existen debates activos en Internet y varias conjeturas sobre el tamaño de la partición Swap, pero es difícil establecer una regla. Sin embargo, esta cuestión es cada vez menos importante, ya que el espacio Swap se utiliza cada vez menos (aunque es necesario), porque los servidores disponen ahora de mucha RAM (memoria de acceso aleatorio o memoria física).
Red Hat sugiere el siguiente principio:
-
Si el tamaño de la memoria física es inferior o igual a 2 GB, entonces la partición de intercambio debe ser el doble del tamaño de la memoria física.
-
En caso contrario, el tamaño de la memoria Swap es igual a la memoria física + 2 GB.
La partición Swap se puede redimensionar, pero esto no se trata en este capítulo.
1. Ver el espacio de intercambio
Para ver el espacio de intercambio existente, utilice los siguientes comandos:
swapon -s
cat /proc/swaps Por ejemplo, este es el espacio existente en un servidor:
[root@rhel-eni ~]# swapon -s
Filename Type Size Used Priority
/dev/dm-1 partition 2097148 0 -1 Podemos ver que tenemos alrededor de 2 GB de Swap en la partición /dev/dm-1. No es forzosamente obvio saber qué es esta partición. Las particiones /dev/dm suelen ser volúmenes LVM.
Para saber de qué partición se trata, visualice los números mayor y menor (los identificadores de hardware internos) del dispositivo:
[root@rhel-eni ~]# ls -l /dev/dm-1 ...Sistema de archivos cifrado
1. Instalación
El cifrado o encriptación consiste en ocultar información para que una persona no autorizada no pueda leerla. Se pueden cifrar archivos, pero también particiones enteras. Para acceder a los datos cifrados, el usuario debe proporcionar una frase de contraseña o una clave almacenada en un archivo.
En el caso del cifrado de particiones, esta clave debe suministrarse cuando se monta la partición, a menudo en el momento del arranque. Una vez montada la partición, ya no es necesario suministrar la clave. Esta es la razón por la que el cifrado de particiones protege contra el desmontaje del disco: si el atacante roba la máquina, cuando intente leer la partición solo tendrá datos cifrados. Pero esta técnica no protege contra el acceso a los datos cuando la partición está montada, por lo que es esencial proteger el acceso a la máquina.
El estándar para cifrar particiones es LUKS (Linux Unified Key Setup-on-disk-format, Configuración por claves unificadas de Linux al formatear el disco), que se instala de forma predeterminada en RHEL 8.8 y 9.2
Se puede elegir cifrar la partición raíz cuando se instala el sistema. Si se define una frase de contraseña, habrá que introducirla cada vez que se arranque el sistema.
Aquí hemos elegido ilustrar la encriptación de una nueva partición...
Arborescencia del sistema de archivos RHEL
1. Una arborescencia adaptada a FHS
El FHS (Filesystem Hierarchy Standard, Estándar de jerarquía del sistema de archivos) define los nombres, rutas y permisos de los archivos y directorios que componen la arborescencia.
De este modo, los sistemas UNIX/Linux que cumplen esta norma garantizan una compatibilidad mínima entre ellos, lo que facilita las cosas a los gestores y diseñadores de software. Red Hat respeta el FHS para su sistema operativo.
La página web asociada a dicho estándar es: https://www.pathname.com/fhs
Este sitio proporciona una explicación bastante completa de la arborescencia FHS, pero aquí explicaremos algunos de los directorios que son cruciales para el gestor.
2. Directorio /dev
El directorio /dev contiene archivos que representan los dispositivos conectados al sistema. Estos archivos son esenciales para que el sistema funcione correctamente.
En él se encuentran:
-
los dispositivos conectados al sistema (por ejemplo, disco duro, ratón, tarjeta de sonido);
-
los dispositivos virtuales creados por el núcleo (ejemplo: sistema de archivos virtual (RAMdisk)).
Estos archivos de dispositivo, conocidos como nodos de dispositivo (device nodes), son creados dinámicamente por el servicio udev, al arrancar el sistema, y cuando se detectan nuevos dispositivos una vez que el sistema ha arrancado.
Los dispositivos en /dev/ son:
-
Bien dispositivos de caracteres:...