
Mantenimiento del sistema en producción
Analizar el sistema
1. La importancia de analizar el sistema
Un sistema no debe instalarse y después olvidarse, sobre todo si se trata de un servidor. Es esencial monitorearlo y darle mantenimiento, como se haría con un coche, por ejemplo.
Los sistemas Linux en general, y Red Hat Enterprise Linux en particular, disponen de varias herramientas para supervisar, mantener y reparar un servidor.
Algunas de estas herramientas son proactivas: le permiten «predecir» el futuro y prevenir los problemas que puedan surgir. Otras herramientas son reactivas: le alertan cuando se produce un problema.
No se puede exagerar la importancia de un buen mantenimiento del servidor. Los gestores deben conocer sus máquinas y analizarlas con regularidad, pero también deben, desde el principio, poner en marcha herramientas que les permitan trabajar con tranquilidad.
También debe saber qué hacer en caso de que se produzca un problema de rendimiento en el servidor. Esto requiere un buen conocimiento del sistema y de las herramientas a su disposición. Existen varios métodos para comprobar el rendimiento del servidor. Por ejemplo, el método USE (Utilización, Saturación y Errores) garantiza que nada quede olvidado durante las verificaciones, y puede resumirse en esta frase:
Para cada recurso, compruebe el uso, la saturación y los errores.
-
Los recursos son los componentes funcionales del sistema operativo: procesadores, memoria, discos, buses de comunicación, interfaces de red.
-
Utilización: la cantidad media de tiempo que el recurso está ocupado realizando su tarea.
-
Saturación: el grado en que el recurso está sobrecargado con trabajo que no puede procesar.
-
Errores: el número de fallos o vulnerabilidades.
Cuando realice comprobaciones periódicas, desconfíe de los promedios: un recurso puede parecer cargado al 50% durante 5 minutos, pero ¿quién sabe si no ha habido un pico del 100% durante 10 segundos en esos 5 minutos?
Ahora puede utilizar las herramientas adecuadas para prevenir los problemas y diagnosticarlos cuando se produzcan.
2. El estándar Syslog
a. Presentación y explicación
Syslog es el estándar para el registro de mensajes en el sistema operativo. Proporciona una gestión centralizada de los mensajes del sistema y de los servicios que se ejecutan en él....
Programar tareas
1. Presentación
Programar tareas es una parte importante de la gestión diaria del sistema. Aunque es cierto que el gestor tiene que realizar ciertas tareas manualmente, muchas tareas de gestión o autogestión se programan y lanzan automáticamente. Algunas de ellas son realmente necesarias; otras ahorrarán tiempo al gestor, como las copias de seguridad automáticas, la supervisión del sistema, la ejecución de scripts, etc.
El principal sistema utilizado para la programación de tareas es Cron. Es esencial para un gestor saber cómo funciona. También necesita conocer los comandos at y batch.
2. Programación periódica usando Cron
a. Presentación
Cron, cuyo nombre proviene del griego Chronos (tiempo), permite a los usuarios del sistema, y especialmente al gestor, programar tareas, también conocidas como jobs, en momentos concretos. En Cron, estas tareas son repetitivas, se realizan de forma regular (del orden de minutos, horas, días, semanas, etc.) y la máquina debe estar permanentemente encendida para poder llevarlas a cabo. Por lo tanto, Cron se adapta bien a los servidores, que están diseñados para funcionar en modo 24/7, sin interrupción.
El servicio crond se instala de manera predeterminada en cualquier sistema Red Hat Enterprise Linux y se inicia cuando se arranca la máquina, de modo que siempre está en funcionamiento.
b. Configurar el servicio
El archivo de configuración del servicio es /etc/crontab.
Este archivo contiene la configuración del servicio crontab, así como la programación de tareas para el sistema.
Las primeras líneas de este archivo contienen información que es necesario conocer cuando se programa una tarea con Cron:
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
HOME=/ -
SHELL=/bin/bash: es el entorno de ejecución de tareas. Cuando se programa un comando en Cron, hay que asegurarse de que el intérprete de comandos (shell) utilizado lo entiende. Por supuesto, se pueden utilizar scripts en diferentes idiomas , siempre que se mencione el intérprete del script (la mayoría de las veces en el script mismo).
-
PATH=/sbin:/bin:/usr/sbin:/usr/bin: si no se especifica una ruta para los comandos programados, se buscarán en esta ruta. También en este caso, asegúrese...
Gestión del tiempo
1. Configuración manual del tiempo
La sincronización de fecha y hora no es algo que deba tomarse a la ligera en un servidor. Para muchos servicios, es un mecanismo esencial, como la verificación de certificados en criptografía asimétrica o el lanzamiento de tareas con Cron.
Por supuesto, se puede ajustar la fecha y la hora simplemente con el comando date:
date MMDDhhmm
date MMDDhhmmAA.ss Con MM para el mes, DD para el día, hh para la hora, mm para los minutos. También se puede añadir AA para el año y .ss para los segundos.
Para obtener la fecha y la hora, simplemente teclee:
date Por ejemplo, para configurar el 25 de diciembre a las 23:59:
[root@cs30 /]# date 12252359
lun. dic. 25 23:59:00 CET 2017
[root@cs30 /]# date
lun. dic. 25 23:59:37 CET 2017
[root@cs30 /]# 2. Configurar el huso horario
La mejor opción es utilizar un servidor horario, que garantice que la hora sea exacta en todas las máquinas.
El protocolo utilizado para la sincronización horaria es el NTP (Network Time Protocol, protocolo de tiempo de red) y se implementa con los servicios ntpd y chrony.
Comience configurando la zona horaria de su servidor:
-
Liste los husos horarios disponibles:
timedatectl list-timezones -
Establezca la zona horaria:
timedatectl set-timezone <huso horario> Por ejemplo:
[root@cs30 /]# timedatectl list-timezones | grep -i madrid
Europe/Madrid ...Gestionar procesos
Como parte de sus tareas de gestión, tendrá que poner en marcha y supervisar diversos programas y procesos.
1. Controlar jobs
¿Cómo gestionar los procesos que se lanzan y los que la máquina ejecuta?
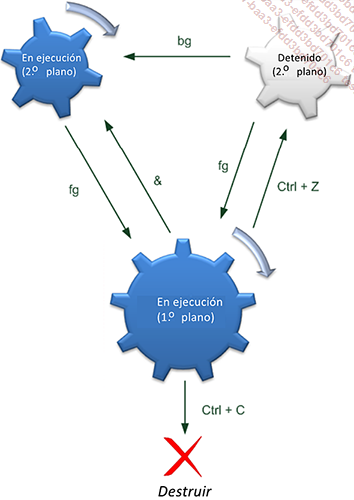
Bash permite controlar los procesos que se lanzan en la línea de comandos. Estos programas se denominan jobs (trabajos). Controlar los trabajos significa detener o suspender su ejecución y, en este último caso, reanudarla a conveniencia. En resumen, esto le permite realizar múltiples tareas en un único shell. Básicamente, los trabajos pueden estar en uno de estos cuatro estados: detenido (en pausa), en primer plano (aún en ejecución), en segundo plano (aún en ejecución, pero permitiéndole utilizar el shell), o completado (trabajo realizado).
Los principales comandos para la gestión de trabajos son los siguientes:
-
Visualizar la lista de trabajos: jobs -l
-
Pausar un trabajo en primer plano: [Ctrl] Z
-
Colocar un trabajo en ejecución en segundo plano: bg %<número de job>
-
Lanzar un trabajo directamente en segundo plano: <comando> &
-
Mover una tarea del fondo al primer plano: fg %<número de job>
-
Destruir un script en bucle: [Ctrl] Z y luego kill %%
Fuente: https://openclassrooms.com/fr/
Pausar un trabajo en primer plano
Por defecto, cuando se lanza un programa desde la línea de comandos, este se encuentra en primer plano, es decir, ya no se tiene acceso a la línea de comandos hasta el final de su ejecución. No se puede lanzar otro programa, a menos que se interrumpa el trabajo con las teclas [Ctrl] C.
En el siguiente ejemplo, lanzamos un ping continuo a una página web. El usuario interrumpe la ejecución del proceso para regresar a la línea de comandos:
[root@rhel6~]# ping www.vodafone.es
PING www.vodafone.es (45.60.74.53) 56(84) bytes of data.
64 bytes from 45.60.74.53 (45.60.74.53): icmp_seq=1 ttl=128 time=45.6 ms
64 bytes from 45.60.74.53 (45.60.74.53): icmp_seq=2 ttl=128 time=78.3 ms
^C
--- www.vodafone.es ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3739ms
rtt min/avg/max/mdev = 45.624/68.138/90.820/17.571 ms
[root@rhel6 ~]# Se puede pausar el trabajo pulsando [Ctrl] Z. El proceso se detiene en ese momento (stopped). Se le asigna un número...
Mejorar la seguridad y la fiabilidad
1. Plan de recuperación ante desastres
Hacer una copia de seguridad de su sistema es esencial. Para garantizar una gestión fluida de su servidor, debe establecer desde el principio una copia de seguridad que le permita volver a poner en marcha su sistema lo antes posible en caso de desastre.
El plan de recuperación en caso de desastre define cómo, en caso de crisis grave en un centro de datos, se reconstruirá su infraestructura y se reiniciarán sus aplicaciones.
El DRP (Disaster Recovery Plan, plan de recuperación ante desastres) debe definirse correctamente. De lo contrario, las consecuencias de un tiempo de inactividad excesivamente largo pueden ser desastrosas y muy costosas para la empresa, especialmente si se han definido SLA (Service Level Agreements, acuerdos de nivel de servicio) con los clientes. A la hora de planificar el proceso de recuperación ante desastres de un servidor, hay que tener en cuenta dos factores:
-
El RTO (Recovery Time Objective, objetivo de tiempo de recuperación): tiempo previsto para restablecer el servicio a su estado original.
-
El RPO (Recovery Point Objective, objetivo de punto de recuperación): estado del servicio al final del proceso de restauración de la actividad.
-
Por ejemplo, en el caso de una base de datos, ¿deben almacenarse todas las transacciones hasta el último segundo o solamente hasta ayer?
-
¿Puede prestarse el servicio en modo reducido o deben estar disponibles todos los servicios?
2. Políticas de almacenamiento y copias de seguridad
Una copia de seguridad o respaldo debe ofrecer:
-
la posibilidad de restaurar sistemas de archivos completos,
-
tener la capacidad de recuperar archivos individuales,
-
idealmente, un historial de archivos.
¿De qué se debe hacer una copia de seguridad?
Las categorías de archivos de los que se debe hacer una copia de seguridad son las siguientes:
-
Sistema operativo «en bruto» y su configuración.
-
Configuración de servicios y software, normalmente localizados en /etc/.
-
Datos de servicios, software y usuarios (bases de datos, directorio /home, etc.).
¿Qué tipos de copia de seguridad realizar?
-
Copia de seguridad completa: se copian todos los archivos en el soporte de destino.
-
Copia de seguridad incremental: solamente se copian los archivos que han cambiado desde la copia de seguridad completa (o desde...
Gestión gráfica usando la consola web Cockpit
1. Presentación
En las páginas de este libro, a veces proporcionamos explicaciones sobre las herramientas gráficas disponibles, correspondientes a los comandos en línea utilizados por el gestor del sistema.
Sin embargo, dada la diversidad de distribuciones, interfaces gráficas y herramientas, estas GUI (Graphical User Interfaces, interfaces gráficas de usuario) son difíciles de mantener, de calidad muy desigual y a menudo están incompletas.
Además, el entorno gráfico necesario para ejecutar estas herramientas de administración (GNOME) es en sí mismo muy engorroso: utiliza recursos de procesador, disco y memoria RAM de forma permanente (y no bajo demanda). Por ello, existen multitud de herramientas de gestión remota, pero de calidad desigual.
Por estas razones, a partir de RHEL 7, Red Hat ha decidido implementar en sus servidores una herramienta de gestión gráfica basada en una interfaz web. Este front-end (interfaz frontal o de usuario), llamado Cockpit, está disponible en muchas distribuciones (incluidas RHEL y Ubuntu) con una interfaz única, fácil de instalar y de asimilar.
Además, Cockpit es extensible y ligero, a diferencia de las herramientas que dependen de una engorrosa interfaz gráfica. De hecho, cuando no está en uso, no utiliza ningún recurso: un módulo escucha las conexiones en el puerto 9090 y lanza Cockpit cuando se le solicita. Es más, no almacena datos de administración en paralelo (en una base de datos, por ejemplo): simplemente lee y escribe en los archivos estándar del sistema, lo que hace muy fácil deshacerse de esta herramienta si así se requiere.
2. Instalación y primera conexión
Cockpit está instalado de manera predeterminada en RHEL 8.8 y 9.2. Si no es así, simplemente instálelo, actívelo y autorícelo en el cortafuegos:
dnf install -y cockpit
systemctl enable --now cockpit.socket
firewall-cmd --add-service=cockpit
firewall-cmd --add-service=cockpit --permanent Una vez hecho esto, solo queda conectarse con un navegador a la dirección IP del servidor en el puerto 9090.
Por ejemplo, tras obtener la dirección IP del servidor, nos conectamos al servicio Cockpit:
[root@eleven ~]# ip a ...Depurar un sistema RHEL
El modo de resolución de problemas consiste en tomar el control de un servidor Red Hat Enterprise Linux que se niega a arrancar. Las razones pueden ser las siguientes:
-
El sistema no arranca: el arranque en nivel 3 o 5 falla, no puede conectarse a una consola local.
-
¿Tal vez se podría acceder a la máquina a través de una conexión remota SSH?
-
El sistema puede estar corrupto o el cargador de arranque puede haber fallado.
-
Ha perdido la contraseña de root del sistema: se puede ver el prompt de conexión shell, pero no puede gestionar la máquina.
Por estas razones y muchas otras, necesitará acceder a su sistema en modo rescate. Le diremos cuáles son y cómo utilizarlos, pero la parte más importante del trabajo recaerá entonces sobre su responsabilidad y sus propias habilidades técnicas para encontrar la causa del fallo.
Con Red Hat Enterprise Linux, hay varias formas de acceder a un sistema dañado.
1. Modo rescate desde DVD
Este es el método recomendado para solucionar problemas.
Gracias al modo rescate (Rescue Mode), se puede acceder a los archivos de un sistema Red Hat Enterprise Linux que se niega a arrancar, bien porque su configuración está dañada, bien porque parte del sistema de archivos está dañado.
El modo Rescate de Anaconda (Anaconda Rescue Mode) utiliza el CD/DVD de instalación de Red Hat Enterprise Linux.
Para arrancar en modo rescate:
Apague la máquina e inserte el CD/DVD de instalación de Red Hat Enterprise Linux 8.8 o 9.2, dependiendo de la instalación.
Reinicie. La máquina deberá mostrar el menú de arranque del CD/DVD.
El BIOS/UEFI debe estar configurado para arrancar desde la unidad de CD/DVD. En algunas máquinas, se puede modificar el dispositivo de arranque pulsando una tecla como [Esc] o [F12]....