
Spring y NoSQL
Introducción
Históricamente, las grandes empresas de la Web han necesitado bases de datos cada vez más extensas debido a un gran número de usuarios o volúmenes muy grandes de datos. Hace algún tiempo, el escalado generalmente se realizaba aumentando la capacidad de la máquina que alojaba la base de datos. De hecho, en una base de datos relacional SQL, las relaciones se establecen a través de claves primarias a las que se hace referencia mediante claves secundarias con la ayuda de índices. Las consultas sobre los datos se realizan mediante uniones (joins) y pasado un tiempo, si hay demasiadas uniones, es fácil que el esquema se vuelva demasiado complejo rápidamente.
La complejidad relativa a las uniones es un argumento que encontramos muy habitualmente. Debe saber que hay aplicaciones compuestas por varios miles de tablas que utilizan combinaciones que funcionan muy bien en Oracle. Oracle puede administrar miles de millones de metadatos (Dictionary-managed database objects: https://docs.oracle.com/en/database/oracle/oracle-database/19/refrn/logical-database-limits.html#GUID-685230CF-63F5-4C5A-B8B0-037C566BDA76). Hay un volumen limitado de datos y un crecimiento exponencial de las dificultades para explotar la base de datos en función de su tamaño.
Los costes se estaban volviendo demasiado altos y, en lugar de usar una sola máquina, se intentó distribuir los tratamientos...
Modelos de datos
Hay cuatro modelos principales:
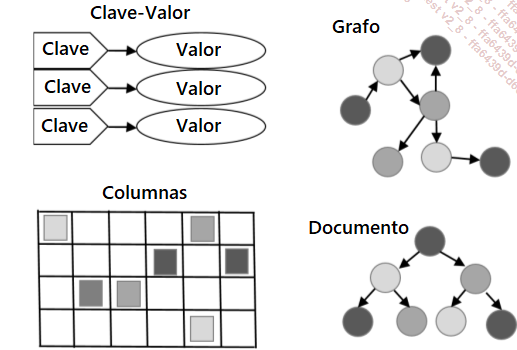
1. Modelo clave-valor
Piense en estas bases de datos como un gran mapa hash (hashmap) almacenado en disco, con la capacidad de establecer metadatos para crear índices. Hay tres grandes bases de datos de este tipo: Project Voldemort, que es un sistema de archivos distribuido propuesto por LinkedIn y que consiste en una implementación gratuita del sistema Dynamo de Amazon; Riak, que está inspirado en Dynamo, y Redis REmote DIctionary Server (servidor de diccionario remoto).
2. Modelo Documentos
En este modelo básico, cualquier documento tiene una estructura compleja persistente (guardada) a la vez. La base de datos está orientada a datos agregados. Necesitamos agrupar las cosas que naturalmente forman parte de un agregado y hacer que persistan en la base de datos. Hay una tendencia a hacer un esquema implícito. Los datos suelen representar entidades concretas. Cabe señalar que, en un sistema clusterizado, si un agregado apunta a otro, el conjunto puede estar en varios nodos.
En una base de datos agregada, la organización del agregado está centrada y optimizada desde el punto de vista de la observación del agregado. Si cambiamos el punto de vista, debemos reorganizar o hacer una composición compleja no optimizada. El identificador de un registro es el equivalente de un sistema clave-valor.
Los agregados son uno de los conceptos centrales del enfoque moderno...
Aspectos principales de la base de datos
Consistencia de los datos
La consistencia está pensada para gestionar los cambios concurrentes. En una base de datos, la coherencia suele estar garantizada por la noción de transacción. Si dividimos un conjunto de información en varias pseudotablas o documentos, queremos que, si uno de los cambios falla, todos los cambios se cancelen. Queremos una actualización atómica. La transacción «unitaria» se ha convertido, después de muchos años, en aceptable y aceptada.
Históricamente, en aplicaciones que involucran múltiples sistemas distribuidos o separados, la noción de transacción era central y teníamos transacciones multifase. Como tal, Spring contiene una gestión de transacciones muy completa que permite gestionar una transacción en una serie de llamadas. Hoy en día, con las aplicaciones sin Stateless, las transacciones son mucho más simples: una transacción, a menudo implícita, por llamada. La transacción «unitaria» se ha convertido, después de muchos años, en aceptable y aceptada.
Para las bases de datos orientadas a documentos, la transacción se debe mantener en el nivel del agregado. La actualización de un agregado puede ser atómica, pero tan pronto como se actualizan varios agregados, se puede producir un conflicto.
La localización...
Por qué y cuándo usar una base de datos NoSQL
La base de datos NoSQL encuentra su lugar allá donde hay naturalmente agregados y donde hay grandes volúmenes de datos. Para las grandes bases de datos muy voluminosas, se usa NoSQL porque no hay una base de datos SQL lo suficientemente grande.
Las siguientes tablas se pueden utilizar para tener una idea de las bases de datos y sus usos:
Consultas rápidas y fáciles:
|
Volumen |
CAP |
Base |
Aplicaciones |
|
Débil |
En RAM |
Redis |
Caché |
|
|
En RAM |
Memcache |
|
|
Ilimitado |
AP |
Cassandra |
Cesta compra |
|
|
Riak |
Tienda |
|
|
Voldemort |
|
||
|
Aerospike |
|
||
|
|
CP |
Hbase |
Histórico |
|
|
MongoDB |
de ventas |
|
|
CouchBase |
|
||
|
DynamoDB |
|
||
Consultas complejas:
|
Volumen |
Tipo |
Base |
Aplicaciones |
|
Disco duro |
ACID |
RDBMS |
Tratamiento |
|
|
Neo4j |
transacción |
|
|
RavenDB |
en línea |
||
|
MarkLogic |
|
||
|
|
Disponibilidad |
CouchDB |
Sitio web |
|
|
|
MongoDB |
|
|
|
SimpleDB |
|
|
|
Ilimitado |
Solicitud |
MongoDB |
Red social |
|
|
personalizada |
RethinkDB |
|
|
|
HBase |
|
|
|
Accumulo |
|
||
|
ElasticSearch |
|
||
|
Solr |
|
||
|
|
Solicitud |
Hadoop |
Big data |
|
|
Analítica |
Spark |
|
|
|
Parallel DWH |
|
|
|
Cassandra |
|
||
|
HBase |
|
||
|
Riak |
|
||
|
MongoDB |
|
||
Sabemos que el éxito de las bases de datos SQL también proviene de su aspecto integrador. Una base de datos SQL es ideal cuando hay que compartir los datos a los que acceden varias aplicaciones o varios nodos en una aplicación clusterizada. La base de datos SQL es ideal para compartir estados entre aplicaciones monolíticas. Por otro lado, si un servicio encapsula su base de datos, si la base...
Problemas con el uso de bases de datos NoSQL
El uso de bases de datos NoSQL induce nuevas decisiones y cambios organizativos. Los DBA tradicionales para grandes bases de datos SQL, como Oracle, Sybase u otros, se enfrentan a la relativa inmadurez de las soluciones NoSQL. La falta de herramientas, experiencia y conocimiento en los equipos no es tranquilizadora.
De hecho, las herramientas existen y el know-how también, pero a menudo se consideran caros y desproporcionados respecto a la escala de un Pizza Team.
Las decisiones se toman en los equipos de desarrollo, que posteriormente deben gestionar el seguimiento y las inconsistencias en la producción. En los proyectos estratégicos, NoSQL se utiliza a menudo para tener TTM (Time To Market o Tiempo de disponibilidad en el mercado) muy cortos. Podemos aprovechar la facilidad de desarrollo y gestionar una gran cantidad de datos. La tendencia actual para los nuevos proyectos es usar bases de datos SQL solo en proyectos no vitales y no estratégicos, con un releasing lento.
Estas bases de datos NoSQL se pueden mantener en discos o simplemente en memoria en el caso de cachés de datos. Más sencillas de gestionar y rápidas, abren la posibilidad de un funcionamiento distribuido entre varios servidores, es decir, en clústeres.
El funcionamiento en clúster proporciona una posibilidad de seguridad operativa al tener en cuenta los problemas de fallos, utilizando la redundancia...
Limitaciones de la base de datos NoSQL
Las consultas SQL permiten hacer casi todo en una base de datos bien diseñada. SQL es conocido y se aprovecha del uso de herramientas como la definición de las seis formas normales.
En NoSQL, se debe ocupar usted mismo de las relaciones entre los documentos y distribuir los datos en los diferentes nodos de un clúster (sharding).
Además, cuando se trata de almacenamiento físico de datos, cada implementación es diferente. A nivel operativo, es necesario hacer algo específico para cada proveedor de base de datos NoSQL. Las API también difieren. Con NoSQL, estamos más cerca del dominio artesanal si lo comparamos con el dominio bien industrializado del mundo SQL tradicional.
Spring y NoSQL
Al igual que con otras bases de datos SQL, Spring facilita el uso de bases de datos NoSQL a través de un API.
Hay una multitud de bases de datos NoSQL. He aquí las más populares:
|
Base |
Características |
|
MongoDB |
Base de datos open source de documentos. |
|
CouchDB |
Base de datos que utiliza JSON para documentos, JavaScript para consultas MapReduce y la API estándar HTTP. |
|
GemFire |
Una plataforma de administración de datos distribuidos que proporciona escalabilidad dinámica, alto rendimiento y persistencia, similar a la de una base de datos. |
|
Redis |
Un servidor de estructura de datos en el que las claves pueden contener cadenas, hashes, listas, conjuntos y conjuntos ordenados. |
|
Cassandra |
Base de datos que proporciona escalabilidad y alta disponibilidad sin comprometer el rendimiento. |
|
memcached |
Sistema open source de alto rendimiento, memoria distribuida y almacenamiento en caché de objetos. |
|
Hazelcast |
Plataforma de distribución de datos open source altamente escalable. |
|
HBase |
Base de datos Hadoop, un almacén de datos grande, distribuido y escalable. |
|
Mnesia |
Un sistema de administración de bases de datos distribuidas que tiene propiedades de software en tiempo real. |
|
Neo4j |
Base de datos de tipo grafo open source de alto rendimiento y calidad profesional. |
Caché de datos
Las cachés dan respuesta al problema de mantener los datos en memoria para que estén disponibles sin tener que volver a cargarlos. Las cachés de datos están cerca de las bases de datos NoSQL clave/valor. Spring hace que sea bastante simple tener una caché sencilla y otra más elaborada, basada en GenFire.
«Solo hay dos problemas complicados en informática: nombrar cosas e invalidar la memoria caché». Famosa cita de Phil Karlton.
1. Caché sencilla
Podemos usar un ResourceBundle para cargar un recurso a fin de almacenar en memoria datos fijos, pero esto no siempre es suficiente. Para simplificar, en el resto de este capítulo diremos que «ocultamos» los datos cuando los hacemos disponibles mediante el uso de una caché de datos.
Spring proporciona un soporte simple para cachear beans gestionados por Spring mediante el uso de la anotación @Cacheable.
Esta anotación indica que el resultado de la llamada a un método (o a todos los métodos de una clase) se puede almacenar en caché. Cada vez que se invoca un método, comprobamos si tenemos en memoria el resultado de una llamada previa para los argumentos dados. También podemos proporcionar una expresión SpEL para calcular la clave a través del atributo key, o una implementación KeyGenerator personalizada que puede anular la predeterminada....
Ocultar datos con GemFire
GemFire es el data grid (grid de datos) en memoria, basado en Apache Geode. Ayuda a estabilizar nuestros servicios de datos bajo demanda para cumplir con los requisitos de rendimiento de las aplicaciones en tiempo real. Admite escalado consistente y homogénea en múltiples data centers, entrega datos en tiempo real a millones de usuarios, tiene una arquitectura orientada a eventos y es ideal para microservicios. Sus principales características son baja y predecible latencia, su escalabilidad y su elasticidad, notificación de eventos en tiempo real, alta disponibilidad y continuidad de la actividad. Es duradero y se ejecuta en la nube.
Para el siguiente ejemplo, usamos la configuración embebida (Embedded), que es la más sencilla para hacer una caché distribuida de alta disponibilidad.
Ejemplo de uso
Clase Application:
@ClientCacheApplication(name = "CachingGemFireApplication",
logLevel = "error")
@EnableGemfireCaching
@SuppressWarnings("unused")
public class Application {
private static final Logger logger= LoggerFactory.getLogger
(Application.class);
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean("Comunidades")
public ClientRegionFactoryBean<String...GemFire como base de datos NoSQL
La clase ApplicationEnableGemfireRepositories:
@ClientCacheApplication(name = "DataGemFireApplication", logLevel =
"error")
@EnableGemfireRepositories
public class ApplicationEnableGemfireRepositories {
public static void main(String[] args) throws IOException {
SpringApplication.run(ApplicationEnableGemfireRepositories.class,
args);
}
@Bean("Comunidad")
public ClientRegionFactoryBean<String, Comunidad>
comunidadRegion(GemFireCache gemfireCache) {
ClientRegionFactoryBean<String, Comunidad> comunidadRegion =
new ClientRegionFactoryBean<>();
comunidadRegion.setCache(gemfireCache);
comunidadRegion.setClose(false);
comunidadRegion.setShortcut(ClientRegionShortcut.LOCAL);
return comunidadRegion;
}
@Bean
ApplicationRunner run(ComunidadRepository comunidadRepository) {
return args -> {
Comunidad galicia = new Comunidad("01",”GALICIA”);
Comunidad...Redis independiente
1. Uso de Redis para la caché de datos
La clase Comunidad sigue siendo la misma que en el primer ejemplo.
El lanzador:
@SpringBootApplication
@EnableCaching
public class Ex3CacheRedis implements CommandLineRunner {
private static final Logger LOGGER =
LoggerFactory.getLogger(Ex3CacheRedis.class);
public static void main(String[] args) {
SpringApplication.run(Ex3CacheRedis.class, args);
}
@Autowired
private ComunidadRepository comunidadRepository;
@Override
public void run(String... args) throws Exception {
comunidadRepository.cacheEvict();
LOGGER.info("27->{}", comunidadRepository.getByCode("27"));
LOGGER.info("44->{}", comunidadRepository.getByCode("44"));
LOGGER.info("51->{}", comunidadRepository.getByCode("51"));
LOGGER.info("27->{}", comunidadRepository.getByCode("27"));
LOGGER.info("44->{}", comunidadRepository.getByCode("44"));
LOGGER.info("51->{}", comunidadRepository.getByCode("51"));
comunidadRepository.patch("27","__ANDALUCIA__");
LOGGER.info("27->{}", comunidadRepository.getByCode("27"));
}
} En el lanzador, tenemos la llamada al método comunidadRepository.cacheEvict() para borrar la caché. Usamos la caché y después parcheamos uno de los valores:...
MongoDB
MongoDB es un sistema de base de datos orientado a documentos, con licencia AGPL y con datos distribuidos en múltiples servidores. No hay ningún esquema de datos. Los controladores están en Apache y la documentación tiene una licencia Creative Common.
Creado en 2007, hubo que esperar hasta la versión 1.4 de 2010 para poder utilizarlo en producción. Los datos están en formato BSON (JSON binario), guardados como colecciones de objetos JSON de varios niveles. En la base de datos, estos registros pueden ser polimórficos con la única restricción de compartir un campo clave principal, llamado «id». Este índice único permite identificar un documento (registro en la base de datos). Las solicitudes se realizan en JavaScript.
La base de datos tiene un intérprete de comandos basado en texto directamente accesible a través del binario Mongo. Existen herramientas gráficas gratuitas, como nosqlbooster4mongo.
1. MongoDB con Spring Boot
Utilizamos la versión Community Edition de MongoDB para nuestras pruebas.
Para pruebas unitarias y de integración, también es posible utilizar las pruebas de contenedor (https://www.testcontainers.org/modules/databases/mongodb/).
Para este ejemplo, ponemos en el pom.xml el starter spring-boot-starter-data-mongodb. El efecto de esto es incluir las dependencias de MongoDB.
No hay diferencias notables con un programa típico que usa SQL.
La clase del lanzador:
@SpringBootApplication
public class Ex1MongoDB implements CommandLineRunner {
private static final Logger LOGGER = LoggerFactory.getLogger(Ex1MongoDB.class);
@Autowired
private CapitalRepository repository;
public static void main(String[] args) {
SpringApplication.run(Ex1MongoDB.class, args);
}
@Override
public void run(String... args) throws Exception {
repository.deleteAll();
repository.save(new Capital("Afganistán", "Kabul", "Asia"));
repository.save(new Capital("África del sur ", "Pretoria", "África"));
repository.save(new...Puntos clave
-
Las bases de datos NoSQL sustituyen a las bases de datos SQL en proyectos que requieren un TTM eficaz.
-
Las bases de datos NoSQL son adecuadas para microservicios o el Big Data.
-
Los equipos de desarrollo gestionan generalmente las bases de datos NoSQL en producción.
-
Es fundamental un buen sharding que coincida con el reparto de datos entre servidores.