![Extrait - LINUX Dominar la administración del sistema [6ª edición]](/libro/linux-dominar-la-administracion-del-sistema-6-edicion-9782409046926_l.webp)
El shell y los comandos GNU
El shell bash
1. Función del shell
Aunque todas las distribuciones ofrecen interfaces gráficas de usuario, un informático profesional que trabaje en un sistema Linux debe estar familiarizado con el funcionamiento del intérprete de comandos (shell) y los principales comandos en modo de caracteres. Por un lado, los sistemas de servidores se suelen instalar sin interfaz gráfica y, por otro lado, es fundamental poder gestionar scripts operativos y administrativos escritos en lenguaje shell y combinando comandos en modo de caracteres.
El intérprete de comandos permite ejecutar instrucciones que se escriben con el teclado o que se leen desde un archivo de script. Este intérprete suele ser un programa de tipo shell. El término shell (concha), de origen Unix, se utiliza en referencia al término kernel (nodo): el shell es una interfaz "alrededor" del kernel de Linux, que opera en modo de caracteres.
Hay varios programas de tipo shell, cada uno con sus propios aspectos específicos. El Bourne Shell, llamado así por su creador Steve Bourne, es el shell más antiguo escrito para Unix. Después, el shell se estandarizó bajo los estándares POSIX.
El shell de referencia para la mayoría de las distribuciones de Linux es bash (Bourne Again Shell), pero hay muchos otros, entre ellos:
-
sh: Bourne Shell
-
ksh: Korn Shell
-
csh: C Shell
-
zsh: Z Shell
-
ash: A Shell
-
dash: Debian Almquist Shell.
El archivo /etc/shells proporciona la lista de los shells instalados en el sistema.
2. Bash: el shell Linux por defecto
El shell bash es un derivado del Bourne Shell. Cumple con los estándares POSIX, pero añade muchas extensiones que son específicas para él.
En las distribuciones recientes de Debian, el shell por defecto es dash, una variante muy similar al shell bash.
a. Un shell potente y libre
El bash, que tiene licencia de código abierto GNU, se proporciona de forma predeterminada con todas las distribuciones de Linux. Incluso viene en versiones para macOS y Windows (a través de la funcionalidad Subsistema de Windows para Linux).
El shell funciona en modo de línea de comandos. Cuando se inicia desde un terminal, se inicializa desde varios archivos, muestra un mensaje de aviso al comienzo de una línea de símbolo del sistema y entra en modo de lectura de teclado. Cuando la línea de comandos se escribe...
La gestión de los archivos
Linux es, al igual que Unix, un sistema operativo orientado a archivos. Todo (o casi) puede estar representado por un archivo, datos (archivos de datos de cualquier tipo, como una imagen o un programa), periféricos (terminales, ratón, teclado, tarjeta de sonido, etc.), canales de comunicación (sockets, pipes con nombre), etc.
1. El sistema de archivos
Un sistema de archivos (File System) define la estructura que organiza la gestión de directorios y archivos en todo o parte de un medio de almacenamiento. Todos los soportes de almacenamiento que se activan (montados) conforman el sistema global de archivos, que se presenta en forma de un único árbol, estructurado por directorios:
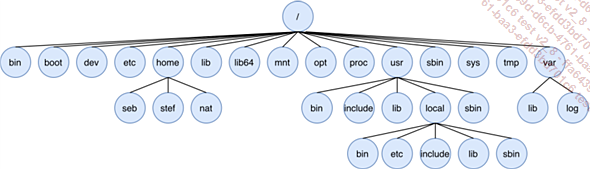
Ejemplo de árbol de directorio Linux
El sistema de archivos de Linux es jerárquico. Describe un árbol de directorios y subdirectorios, a partir de un elemento básico llamado raíz (root directory).
2. Los diferentes tipos de archivos
Distinguimos tres tipos de archivos: ordinario, directorio, especial.
a. Los archivos ordinarios o regulares
Los archivos ordinarios se llaman también archivos regulares, (ordinary regular files). Son archivos que contienen datos. El sistema los considera una secuencia de bytes. Pueden contener texto, imágenes, sonido, un programa ejecutable, etc.
El comando file se utiliza para obtener información sobre la naturaleza del contenido de un archivo.
Ejemplo
$ file /usr/bin/bash /etc /etc/passwd
/usr/bin/bash: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV),
dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=
5d82a44f2a4466ff21f763af86b004d1fcb3a8f1, for GNU/Linux 3.2.0, stripped
/etc: directory
/etc/passwd: ASCII text El sufijo (o extensión) de un nombre de archivo no tiene ningún significado especial para el sistema. Es opcional.
Ver el contenido de un archivo de texto
El comando cat NombreFic muestra el contenido del archivo NombreFic.
El comando no comprueba que el archivo solo contenga caracteres visualizables.
Ejemplo
$ cat /etc/hostname
srvdeb b. Los directorios
Para Linux, al igual que para Unix, los directorios son archivos de un tipo particular. Se utilizan para estructurar el espacio en disco en una estructura...
Buscar archivos con el comando find
El comando find permite buscar archivos dentro de la estructura del sistema de archivos en función de diferentes criterios, y puede ejecutar un comando en cada elemento correspondiente a la búsqueda.
Sintaxis
find [PuntoDeInicio] [Opciones] [Expresión] El comando busca en todo el árbol desde el directorio principal especificado. Por defecto, busca desde el directorio actual (el archivo "."). Sin una opción particular de búsqueda, muestra todos los elementos contenidos en el árbol desde el directorio principal, incluidos los elementos cuyos nombres comienzan con el carácter de punto.
El comando find no se detiene cuando hay un error, muestra un mensaje y pasa a la búsqueda del siguiente elemento. Lo más habitual es que el mensaje indique que los permisos de acceso del directorio no permiten que el comando enumere su contenido.
Ejemplo
Todos los elementos del repertorio de conexión:
$ cd
$ find
.
./.local
./.local/share
./.local/share/tracker
./.local/share/tracker/data
./.local/share/tracker/data/tracker-store.log
./.local/share/tracker/data/tracker-store.ontology.log
./.local/share/tracker/data/.meta.isrunning
./.local/share/gvfs-metadata
./.local/share/gvfs-metadata/uuid-f6d93569-f478-4a37-8387-aacdcb125a6f
[...]
./enlace3
./.bashrc
./.profile
./.bash_logout
./rep2
./rep2/fic1
[...]
./enlace1
./enlace2
./.bash_history
./fic1
./paquetes
./paquetes/lynx_2.9.0dev.6-3~deb11u1_amd64.deb 1. Criterios de búsqueda
Las opciones permiten definir los criterios de búsqueda. Si hay varios, puede combinarlos usando una Y lógica (criterio1 Y criterio2).
a. Buscar por nombre
-name permite una selección por nombre de archivo o directorio. Es posible utilizar los caracteres genéricos vistos anteriormente. En este caso, el criterio debe ir entre comillas para evitar ser interpretado por el shell.
Ejemplo
Lista de todos los archivos, del directorio actual, cuyos nombres comienzan con fic:
$ find . -name "fic*"
./rep2/fic1
./fic1 b. Buscar por tipo
-type permite una selección...
El editor vi
La mayoría de los archivos de configuración de Linux son archivos de texto. Por otro lado, es común tener que crear o modificar scripts de shell. Las distribuciones de Linux ofrecen diferentes editores de texto, algunos funcionan en modo gráfico y otros en modo de caracteres. De todos estos editores, el más utilizado es, sin duda, vi (visual editor). Originario de Unix, creado por Bill Joy, existe en todos los sistemas similares a Unix y se incluye con todas las distribuciones de Linux.
1. Presentación
El editor vi en Linux se llama vim (vi iMproved). Es compatible con vi, pero tiene funcionalidades adicionales. Por lo general, el comando vi existe, pero está asociado con el ejecutable vim.
Sintaxis
vi [options] Archivo [Archivo2 ...] vi es un editor de texto que funciona en modo carácter (aunque hay versiones con interfaz gráfica). Esto permite poder ser utilizado desde un terminal.
2. Funcionamiento
Una vez en el editor, este último gestiona tres modos de funcionamiento:
-
Modo comando: las inserciones representan comandos. Se accede a ellos al pulsar en [Esc]. Cada tecla o combinación de teclas activa una acción (eliminar, insertar, mover, copiar, pegar, etc.).
-
Modo inserción: este es el modo utilizado para insertar texto.
-
Modo línea de comandos: una línea en la parte inferior de la pantalla permite insertar comandos especiales, validados con la tecla [Entrar]. Se accede desde el modo comando, con la tecla «:».
Cuando se inicia vi, el editor está en modo de comando. Los comandos de vi están asociados a una o más teclas: a, i, o, yy, p, dw, J, etc. vi distingue entre mayúsculas y minúsculas, por ejemplo, los comandos o y O no tienen el mismo efecto.
Para pasar del modo de comando al modo de entrada, debe ejecutar un comando de adición o inserción: a, i, o, etc. Para salir del modo de entrada y volver al modo de comando, utilice la tecla [Esc].
3. Los comandos básicos de vi
a. Pasar al modo introducción de datos
Se deben pasar los comandos siguientes al editor en modo comando.
|
Comando |
Acción |
|
a |
Añadir después del carácter actual. |
|
A |
Añadir al final de línea. |
|
i |
Insertar antes del carácter actual. |
|
I |
Insertar al principio de la línea. |
|
o |
Apertura de una línea debajo de la línea actual. |
|
O |
Apertura de una línea... |
Las redirecciones de entradas/salidas estándares
Los conceptos de entrada/salida estándares y redirección, ofrecen una gran flexibilidad a la hora de gestionar los programas ejecutados en Linux.
1. Entradas/salidas estándares
Un programa en ejecución tiene tres archivos abiertos: uno en modo de solo lectura y dos en modo de escritura. Estos tres archivos son las entradas/salidas estándares. El programa los identifica por su número de descriptor o nombre simbólico: 0 para la entrada estándar stdin (archivo abierto en modo solo lectura), 1 para la salida estándar stdout y 2 para la salida de error estándar stderr (archivos abiertos en modo solo escritura).
Un programa Linux no gráfico suele utilizar estas entradas/salidas estándar para comunicarse con el mundo exterior:
-
La entrada estándar, en modo lectura, permite leer información a medida que se ejecuta.
-
La salida estándar, en modo escritura, permite proporcionar resultados de procesamiento.
-
La salida de error estándar, en modo escritura, permite proporcionar mensajes de error o información adicional sobre su procesamiento.
2. Entradas/salidas estándar por defecto
Por defecto, el shell asocia la pantalla del terminal y el teclado con las entradas/salidas estándar:
-
La entrada estándar, en modo lectura, está asociada con el teclado. Por esta razón, cuando escribe una línea...
La redirección
La redirección de entrada/salida estándar es un mecanismo que permite ampliar de forma flexible la funcionalidad de los programas que se ejecutan en Linux. De hecho, cuando se inicia el programa, puede especificar los archivos asociados con sus entradas/salidas estándares. Dado que Linux es un sistema operativo orientado a archivos, todo o casi todo se puede ver como un archivo. Por lo tanto, es posible redirigir la lectura o escritura de un programa a un archivo ordinario, un archivo especial asociado a un dispositivo (pantalla, teclado, impresora, unidad de cinta, conexión de red, etc.) u otro programa (pipe). Este mecanismo es transparente para el programa, que utiliza su entrada/salida estándar en modo de lectura o escritura, sin saber a qué archivos corresponden.
1. Redirección de la salida estándar
El carácter > se utiliza para redirigir la salida estándar. Después de este carácter, se especifica la ruta del archivo que se va a asociar a la salida estándar.
El shell escribe el archivo especificado, lo crea si no existe, y lo vacía de su contenido de haberlo. A continuación, ejecuta el comando y asocia el archivo a su salida estándar.
Ejemplo
Redireccionamiento de la salida estándar del comando ls:
$ ls -l > resultado
$ cat resultado
total 24
-rw-r--r-- 1 pba pba 7 16 mayo 12:11 fic1
-rw-rw-rw- 1 pba pba 0 17 mayo 09:39 ficPublico
lrwxrwxrwx 1 pba pba 4 16 mayo 12:10 enlace1 -> fic1
-rw-r--r-- 1 pba pba 27 16 mayo 11:53 enlace2
-rw-r--r-- 1 pba pba 27 16 mayo 11:50 enlace 3
drwxr-xr-x 2 pba pba 4096 16 mayo 11:46 paquetes
drwxr-x--- 2 pba pba 4096 17 mayo 09:52 rep1
drwxr-xr-x 2 pba pba 4096 16 mayo 08:12 rep2
-rw-r--r-- 1 pba pba 0 19 mayo 14:21 resultado El comando no muestra nada. Escribe sus resultados en su salida estándar, es decir, en el archivo resultado creado por el shell. Observe que cuando el comando realizó el listado del directorio actual, el archivo existía, pero estaba vacío.
El mismo comando...
Comandos de filtro
Un filtro es un programa capaz de leer datos de su entrada estándar y escribir sus resultados en la salida estándar. Este es el caso de muchos comandos de utilidades de Linux. Con pipes y redireccionamientos, los comandos se pueden combinar fácilmente para realizar varios procesos, especialmente en archivos de texto.
1. Contar líneas, palabras y caracteres
El comando wc (word count) permite contar líneas, palabras y caracteres de los archivos que se pasan como argumentos o líneas leídas desde su entrada estándar.
Sintaxis
wc [-l|c|w] [fic1 ... ficN] -
-l: número de líneas.
-
-c: número de bytes.
-
-w: número de palabras.
-
-m: número de caracteres.
Ejemplo
$ wc lista
12 48 234 lista El archivo lista contiene 12 líneas, 48 palabras y 234 caracteres.
Contar el número de filas generadas por un comando ls:
$ ls -l | wc -l
19 2. Selección de líneas
Los comandos de tipo grep (Global Regular Expression Parser) permiten seleccionar líneas de texto en función de diferentes criterios. Pueden procesar archivos cuyos nombres pasan como argumentos o leer los datos en su entrada estándar.
Consiste en extraer filas de un archivo en función de varios criterios. Para hacer esto, dispone de tres comandos: grep, egrep y fgrep, que leen datos bien desde un archivo de entrada, bien desde su entrada estándar.
a. grep
La sintaxis del comando grep es:
grep [Opciones] modelo [Archivo1...] El modelo (pattern) es una cadena de caracteres que forman una expresión regular. Puede estar compuesto por caracteres simples o caracteres especiales de expresiones regulares (las que se ven en la sección dedicada al editor vi). Para evitar que el shell no interprete estos caracteres, es recomendable ser prudente y encerrar el modelo con comillas simples o dobles o proteger los caracteres especiales con un \.
Ejemplo
$ cat fic4
Cerdo
Ternera
Buey
rata
Rata
buey Mostrar las líneas del archivo que comienzan con una b o una B:
$ grep "^[bB]" fic4
Buey
buey Opciones:
-
-v búsqueda inversa: muestra las filas que no coinciden con los criterios.
-
-c devuelve el número de filas encontradas, sin mostrarlas.
-
-i no hay distinción entre mayúsculas y minúsculas....
Otros comandos útiles
Linux tiene una gran cantidad de comandos muy útiles para administrar archivos. Estos son algunos de ellos.
1. Recuperación de una parte de una ruta de acceso
El comando basename se utiliza para extraer la parte del nombre de archivo de una ruta de acceso de archivo.
Ejemplo
$ basename /tmp/pba/lista
lista El comando dirname hace lo contrario, es decir, extrae la parte de la ruta de acceso, sin el nombre del archivo.
Ejemplo
$ dirname /tmp/pba/lista
/tmp/pba 2. Comparación de archivos
Hay varios comandos que se pueden usar para comparar el contenido de dos archivos.
a. diff
El comando diff indica las diferencias entre dos archivos especificados y los cambios que se deben realizar en ellos para que su contenido sea idéntico.
Sintaxis
diff [-b] fic1 fic2 La opción -b ignora los caracteres en blanco (blank).
El comando diff muestra los comandos de vi que permiten hacer que los archivos sean idénticos. El símbolo < denota el archivo fic1, el símbolo >, el archivo fic2.
Ejemplo
$ cat lista
Producto objeto precio cantidades
ratón óptico 30 15
duro 30giga 100 30
duro 70giga 150 30
disco zip 12 30
disco blando 10 30 ...La gestión de los procesos
Cualquier programa que se ejecute en un sistema Linux está asociado con, al menos, un proceso, administrado por el kernel y se inscribe en una entrada en la tabla de procesos, enumerando sus diversos atributos. Un proceso de Linux siempre está asociado a un proceso padre, por lo que el conjunto de procesos forma un árbol.
1. Atributos de un proceso
A continuación, se ofrece una lista de los principales atributos de un proceso:
-
Su identificador de proceso PID (process ID): cada proceso se identifica con un número único. El primer proceso es creado por el kernel, con PID 1 suele ser el programa init o systemd.
-
El ID de proceso de su proceso padre PPID (Parent Process ID): un proceso siempre es creado por otro proceso (excepto el proceso inicial, creado por el kernel), a través de la llamada de sistema fork.
-
Un identificador de usuario UID (User ID) y un identificador de grupo GID (Group ID): por defecto, se corresponden con el UID y el GID del grupo principal del usuario que inició el proceso. Estos elementos determinan los permisos para acceder a los objetos del sistema (archivos, directorios, etc.). Los procesos secundarios heredan esta información.
-
Duración y prioridad del proceso: la duración del proceso corresponde al tiempo de ejecución consumido desde la última invocación. En un entorno multitarea, el tiempo de procesador se comparte entre los procesos y no todos tienen la misma prioridad. Los procesos de más alta prioridad se ejecutan primero. Cuando un proceso está inactivo, su prioridad aumenta para poder ser ejecutado. Cuando está activo, su prioridad baja para dejar paso a otro. El planificador de tareas del nodo es el que gestiona las prioridades y los tiempos de ejecución.
-
Directorio de trabajo actual: tras su inicio, se configura el directorio actual del proceso (desde el cual se inició). Este directorio servirá de base para las rutas relativas.
-
Archivos abiertos: tabla de los descriptores de archivos abiertos. Por defecto, tres descriptores están asociados a los archivos: 0, 1 y 2 (las entradas/salidas estándares). Con cada apertura de archivo o de nuevo canal, la tabla se rellena. Cuando termina el proceso, se cierran todos los archivos descriptores.
Puede encontrar más información, como el tamaño de la memoria...
Más información sobre bash
Los programas de shell, especialmente bash, ofrecen funcionalidades muy avanzadas. En esta parte del capítulo, se presentan algunas de ellas.
1. Alias
Un alias es una abreviatura de una línea de comandos, declarada en el shell actual y que solo existe hasta el final de la sesión (por lo que los alias a menudo se definen en los archivos de inicialización del shell). Se define con el comando alias.
Sintaxis
Alias NombreAlias='Línea de commando' Sin argumentos, el comando enumera los alias disponibles.
Ejemplo
Lista de alias predeterminados para una cuenta de usuario en una distribución de RHEL:
$ alias
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias xzegrep='xzegrep --color=auto'
alias xzfgrep='xzfgrep --color=auto'
alias xzgrep='xzgrep --color=auto'
alias zegrep='zegrep --color=auto'
alias zfgrep='zfgrep --color=auto'
alias zgrep='zgrep --color=auto' Creación de un alias:
$ alias mils='ls -il'
$ mils /
total 28
30026...Las variables
Una variable es un nombre lógico asociado con una ubicación dentro de un área de memoria particular de un proceso: su entorno. El contenido de una variable, la mayoría de las veces una cadena de caracteres, se puede usar en la línea de comandos o por programas.
1. Nombre de variable
El nombre de una variable obedece a ciertas reglas:
-
Está compuesto por letras minúsculas o mayúsculas, números y el carácter subrayado.
-
No puede comenzar con un número (excepto para variables predefinidas).
-
El tamaño máximo del nombre es indefinido.
2. Declarar y asignar
Se declara una variable en cuanto se le asigna un valor. Se efectúa la asignación con el signo =, sin espacio antes ni después del signo.
Ejemplo
var=Hola 3. Acceder y visualizar
Para acceder al contenido de una variable, coloque el carácter $ delante de su nombre. Cuando el shell analiza una línea de comandos, considera como nombre de variable la secuencia de caracteres entre $ y el primer carácter que no puede figurar en un nombre de variable. Si existe una variable con este nombre, el shell reemplaza la cadena $nomvar con su contenido. De lo contrario, con una cadena nula.
Ejemplo
Creación y uso de la variable mitmp:
$ mitmp=/tmp/pba
$ cp fic $mitmp
$ ls -l fic /tmp/pba
-rw-r--r--. 1 pba pba 8 15 mayo 16:53 fic
-rw-r--r--. 1 pba pba 8 22 mayo 21:35 /tmp/pba El comando env muestra una lista de variables conocidas del shell actual y sus procesos hijo. El comando set sin argumentos muestra una lista de todas las variables conocidas del shell actual (así como otros tipos de elementos).
Ejemplo
La variable creada en el ejemplo anterior se lista por set, no por env:
$ env
SHELL=/bin/bash
HISTCONTROL=gnoredups
HISTSIZE=1000
HOSTNAME=srvrh
PWD=/home/pba
LOGNAME=pba
XDG_SESSION_TYPE=tty
MOTD_SHOWN=pam
HOME=/home/pba
LANG=es_ES.UTF-8
...
$ env | grep mitmp
$ set | grep mitmp
mitmp=/tmp/pba Una variable puede contener caracteres especiales (espacio, punto y coma, punto, *, $, etc.). En este caso, suele ser necesario encerrar su contenido entre comillas simples o dobles durante su asignación o preceder...
Configuración del bash
Dependiendo de cómo se inicie, el shell ejecuta varios archivos de configuración. Un archivo de configuración es un script shell que contiene una secuencia de comandos para configurar el entorno del usuario.
1. Archivos de configuración
El shell bash se puede ejecutar en varios modos:
-
shell interactivo de conexión (login shell),
-
shell lanzado por otro shell, ya sea explícitamente o para ejecutar un script.
a. Shell de conexión
El shell de conexión se inicia después de introducir el login y la contraseña en la consola. Este es el programa cuya ruta de acceso se especifica en el último campo de la línea de la cuenta de usuario en /etc/passwd.
En este modo, el bash ejecuta, si existen y en este orden, los siguientes archivos:
-
/etc/profile
-
/etc/profile/profile.d/*
-
$HOME/.bash_profile
-
$HOME/.bash_login
-
$HOME/.bashrc
Cuando se desconecta, intenta ejecutar:
-
$HOME/.bash_logout
b. Shell simple
Un shell se puede lanzar desde otro shell, ya sea especificándolo en la línea de comandos o automáticamente cuando se ejecuta un script.
En este caso, solo ejecuta un archivo de configuración, si existe:
-
$Home/.Basharq
Los shells diferentes a bash funcionan con los mismos principios, pero los nombres de los archivos de configuración pueden ser diferentes (.profile, .kshrc, etc.).
2. Configuración del shell con el comando set
Las opciones de shell...
Programación shell
El shell no es un simple intérprete de comandos, sino que dispone de un verdadero lenguaje de programación que permite la gestión de las variables, el control del flujo y bucles, funciones, etc.
1. Estructura y ejecución de un script shell
Un script de shell es un archivo de texto que contiene líneas de comandos de shell. Cuando un script es ejecutado por un shell, cada línea se lee, interpreta y ejecuta como si fuera una línea de comandos interactiva.
Una fila puede constar de comandos internos o externos, comentarios o estar vacía. Se permiten varias instrucciones por línea, separadas por el carácter; o enlazadas condicionalmente por && o ||. El ; equivale a un salto de línea. También puede usar el carácter & para ejecutar una línea en segundo plano.
Antes de ejecutar una línea de comandos, el shell la analiza, la interpreta y, a continuación, si se trata de un comando externo, busca la ruta de acceso a su archivo ejecutable.
A continuación, el shell solicita que se ejecute el archivo. Si los permisos de acceso del usuario asociado al shell lo permiten (permiso x), se crea un nuevo proceso para ejecutar el archivo. En el caso de un archivo de script, este proceso ejecuta un shell que leerá el archivo de script línea por línea y ejecutará cada línea en el orden del archivo.
El comando chmod permite dar al propietario el permiso de ejecución sobre un archivo de script.
Sintaxis
$ chmod u+x miscript Para solicitar la ejecución de un archivo de script, se puede especificar su ruta de acceso o, si se coloca en un directorio al que hace referencia la variable PATH, especificar su nombre.
También se puede ejecutar de manera explícita por un shell hijo, en cuyo caso el permiso de lectura en el archivo es suficiente para la ejecución.
Sintaxis
bash RutaScript Ejemplo
Creación y ejecución de un script shell:
$ vi miscript
echo inicio de mi script
date
who
echo fin de mi script
$ ./miscript
-bash: ./miscript: Permisos no concedidos Nos damos el permiso de ejecutar el script:
$ chmod u+x miscript
$ ./miscript
inicio de mi script
martes 23 mayo 2023 09:51:20 CEST
pba pts/0 2023-05-23...Multiplexores de terminal
Las herramientas screen y tmux permiten administrar varias ventanas en modo de caracteres dentro del mismo terminal. Los ejemplos mostrados se basan en screen, pero se pueden aplicar a tmux, que utiliza la misma sintaxis.
Estas herramientas de software ofrecen, entre otras, las siguientes funcionalidades:
-
Abrir varias ventanas de shell desde una sola conexión ssh.
-
Mantener abiertas las conexiones ssh en caso de problemas de red (conmutación automática por error).
-
Desconexión y reconexión de sus sesiones de shell y ssh desde varias ubicaciones (y redes).
-
Ejecutar un comando de shell de larga duración sin tener que mantener una sesión activa.
1. Uso
a. Instalación y ayuda
La instalación se realiza con el paquete screen.
Una vez que se inicia el comando screen, puede acceder a la ayuda pulsando sucesivamente [Ctrl] a y luego ?.
b. Ventanas
La secuencia [Ctrl] ac abre una nueva ventana de conexión. Las diferentes ventanas están numeradas del 0 al n.
Para cambiar a la ventana X, usamos la secuencia de teclas [Ctrl] a X.
Las secuencias [Ctrl] a n (next) y [Ctrl] a p (previous) permiten pasar a la ventana siguiente o anterior.
El comando exit (o [Ctrl] d) cierra la ventana actual.
c. Separarse y volver a unirse
La secuencia de teclas [Ctrl] a d se utiliza para "separar" una ventana. La ventana continúa ejecutándose en segundo plano después de la salida...