
Ingeniería inversa
Introducción
1. Presentación
La técnica de ingeniería inversa (reverse engineering en inglés) consiste en estudiar un objeto (en nuestro caso un malware) para comprender su funcionamiento. En informática, eso se traduce por analizar el código de máquina de un programa; en nuestro caso, un malware. Dado que los malwares no se difunden con su código fuente y que no es posible encontrar códigos de malwares desarrollados en C o en C++, es necesario utilizar técnicas de ingeniería inversa para estudiar su funcionamiento interno. El analista estudiará el código en ensamblador del malware, función tras función.
Este código en ensamblador está disponible desensamblando el archivo binario.
El código en ensamblador no es tan fácil de leer como el código fuente. En efecto, se trata de un lenguaje de bajo nivel que manipula directamente instrucciones CPU y la memoria física.
Vamos a interesarnos principalmente en el ensamblador x86 (de 32 bits), aunque una pequeña sección presentará las principales diferencias entre el x86 y el x64 (de 64 bits) desde el punto de vista de la ingeniería inversa. En la actualidad, el 80 % de malwares están compilados en 32 bits, para poder impactar en el mayor número de máquinas posible (los sistemas Windows de 64 bits admiten...
¿Qué es un proceso de Windows?
1. Introducción
Cuando se ejecuta un proceso en Windows, el sistema operativo va a crear automáticamente un espacio en la memoria para este y un primer subproceso (thread). Todos los procesos en ejecución disponen de una estructura llamada Process Environment Block (PEB) que los describe. Cada proceso dispone de uno o vario threads. Cada thread posee su propia pila (stack, ver capítulo Técnicas de ofuscación) y una estructura que lo define llamada TEB (Thread Environment Block). Los threads pueden acceder a la memoria del proceso. He aquí un esquema que resume un proceso:

2. Process Environment Block
Se puede leer el contenido del PEB de un proceso. He aquí un ejemplo de PEB de un proceso cmd.exe visto por el depurador de Microsoft: WinDBG. La dirección de memoria en la que se encontrará la estructura PEB esta almacenada en $PEB:
0:001> r $PEB
$peb=0000000301292000 A partir de esta dirección se puede comprobar el contenido de la estructura PEB:
0:001> dt _PEB 0000000301292000
ntdll!_PEB
+0x000 InheritedAddressSpace : 0 ''
+0x001 ReadImageFileExecOptions : 0 ''
+0x002 BeingDebugged : 0x1 ''
+0x003 BitField ...Ensamblador x86
1. Registros
El x86 es una arquitectura en la que el procesador utiliza principalmente registros de 32 bits para almacenar información. Cada registro contiene un número codificado en 32 bits, aunque este número puede verse como dos de 16 bits o 4 de 8 bits. Para mejorar su comprensión, ilustraremos este punto con un ejemplo.
El número hexadecimal 0xC0DEBA5E es un entero de 32 bits. En efecto, puede representarse por los siguientes 32 bits:
|
Hexadecimal |
C |
0 |
D |
E |
B |
A |
5 |
E |
|
Binario |
1100 |
0000 |
1101 |
1110 |
1011 |
1010 |
0101 |
1110 |
Puede verse como dos enteros de 16 bits, 0xC0DE y 0xBA5E, o como cuatro enteros de 8 bits, 0xC0, 0xDE, 0xBA y 0x5E. Es importante habituarse a realizar este pequeño ejercicio, pues el ensamblador hace a menudo un uso abusivo de estas distintas representaciones.
Para facilitar la explicación, se utilizan comúnmente términos específicos para distinguir estos números de distintos tamaños: un byte es un número de 8 bits; una palabra es un número de 16 bits, es decir, 2 bytes; un double es un número de 32 bits, es decir, dos palabras o 4 bytes.
Las arquitecturas x86 presentan principalmente 16 registros diferentes que se dividen en cinco tipos: registros generales, registros de índice, registros de punteros, registros de segmentos y por último los registros de estado o banderas (flags en inglés).
Registros generales
Existen cuatro registros de este tipo: EAX, EBX, ECX y EDX.
Estos registros suman 32 bits, pero pueden descomponerse en subregistros más pequeños. En este caso, su notación cambia. He aquí un ejemplo para EAX:
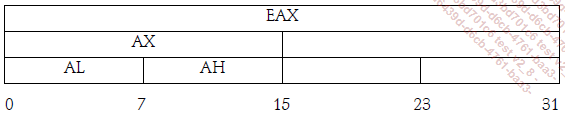
Las cifras debajo de la ruta corresponden a los bits del registro. La E presente al inicio de cada registro corresponde a Extended (Extendido). Los 32 bits son una especie de extensión de los 16 bits, de modo que los registros mantienen los mismos nombres agregando una E delante.
Como anécdota diremos que estas notaciones bárbaras provienen de las primeras arquitecturas de 8 bits, que incluían 4 registros generales: A, B, C y D. Con la aparición de las máquinas de 16 bits, se utilizaba la notación AX, BX, CX y DX, donde la X significaba eXtended. Cada uno de estos registros se descomponía en dos registros de 8 bits: Low para la parte inferior y High para la superior; de ahí...
Ensamblador x64
1. Registros
En la arquitectura x64, los registros tienen un tamaño de 64 bits. Los registros empiezan por una R. Por ejemplo, la versión de 64 bits del registro EAX es RAX (incluso aunque EAX exista y se represente con 32 bits).
He aquí el esquema:
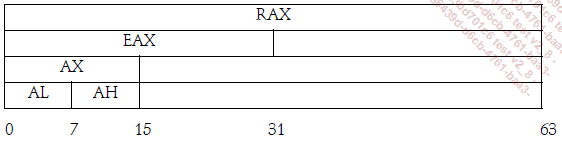
Existen, además de los registros citados en la sección dedicada al ensamblador x86, nuevos registros que van de R8 a R15.
2. Parámetros de las funciones
Hemos visto cómo en la arquitectura x86 los parámetros de las funciones se pasaban mediante la pila y la instrucción PUSH. En 64 bits, el paso de argumentos es diferente:
-
el primer argumento se pasa mediante el registro RCX;
-
el segundo argumento se pasa mediante el registro RDX;
-
el tercer argumento se pasa mediante el registro R8;
-
el cuarto argumento se pasa mediante el registro R9;
-
el resto de los argumentos (si los hay) se pasan mediante la pila, como en la arquitectura x86.
Análisis estático
1. Presentación
El análisis estático consiste en examinar el código en ensamblador sin ejecutar el binario asociado. Utilizando este método es posible analizar cualquier tipo de binario en cualquier arquitectura. No existe riesgo de infección por el malware, puesto que este no se ejecuta. La ventaja del análisis estático es precisamente que no depende de la ejecución. De este modo, la mayoría de los comportamientos del binario pueden deducirse estáticamente, incluso aquellos difíciles de observar con su ejecución. Por ejemplo, el comportamiento de un RAT (Remote Access Tool) depende de los comandos que ejecuta el atacante. Sin interacción por parte del atacante, es difícil observar el comportamiento del RAT durante su ejecución. El análisis estático no está sometido a esta limitación.
Para realizar un análisis estático, es necesario utilizar un desensamblador a fin de decodificar el código máquina del malware en lenguaje ensamblador. Esta aplicación debe permitir comentar las instrucciones, renombrar las variables, las funciones o incluso presentar una vista gráfica del flujo de ejecución. El trabajo en el caso de un análisis estático consiste en comentar las instrucciones, comprender las funciones, así como sus argumentos, para poder comprender el flujo de ejecución del malware y saber qué es lo que hace realmente sobre la máquina infectada.
2. Ghidra
a. Presentación
Ghidra es una herramienta de análisis estático publicada por la NSA (Agencia Nacional de Seguridad de los EE. UU.) al principio de 2019. Se puede descargar gratuitamente de: https://ghidra-sre.org/ y su código fuente está disponible en GitHub: https://github.com/NationalSecurityAgency/ghidra/releases.
Esta herramienta permite desensamblar archivos binarios. Muestra el lenguaje ensamblador, pero también contiene un descompilador que permite obtener un pseudocódigo C del binario que se está analizando.
Ghidra está desarrollada en Java y funciona tanto en Windows, Linux como en macOS. Es compatible con una amplia variedad de arquitecturas, como x86 (32 y 64 bits), y también ARM, AARCH6, PowerPC, MIPS, etc. Puede analizar tanto archivos Windows (formato...
Análisis dinámico
1. Presentación
A diferencia del análisis estático, el análisis dinámico consiste en estudiar las acciones del binario durante su ejecución. Es importante destacar que en este caso el binario se ejecuta realmente y la máquina sobre la que se ejecuta se verá infectada por el malware que se está analizando. Es primordial, por tanto, trabajar en una máquina virtual.
Para realizar un análisis dinámico, el analista necesita un depurador. Un depurador permite ejecutar un binario instrucción por instrucción, así como situar puntos de interrupción (o breakpoints) para detener la ejecución del binario y consultar su estado. En esta sección utilizaremos dos depuradores: X64dbg y WinDbg.
Cada analista tiene su forma de trabajar con el depurador, pero lo importante es familiarizarse con él. Es imprescindible en el kit de herramientas de cualquiera que desee analizar malware.
2. X64dbg
a. Presentación
X64dbg es un depurador de 32 bits para Windows. Puede descargarse gratuitamente en: https://x64dbg.com/. Este depurador permite seguir fácilmente la ejecución de un programa en Windows. Permite ver las instrucciones ejecutadas, el estado de la memoria y de los registros. También permite situar puntos de interrupción en instrucciones particulares, durante el acceso a ciertas zonas de memoria o durante la ejecución de funciones específicas. Cada una de estas funcionalidades se describe en esta sección. Existen otros depuradores para Windows. La ventaja de X64dbg es que admite el lenguaje Python para automatizar ciertas tareas.
X64dbg consta de dos ejecutables: x86dbg.exe, para analizar binarios de 32 bits, y x64dbg.exe, para los de 64 bits. He aquí la interfaz de Immunity Debugger tras su arranque:
Es posible depurar un binario en ejecución (en la jerga a esta acción se la denomina «vincularse» a un programa) o ejecutar un nuevo binario. En este caso, X64dbg se sitúa a nivel de la función main() del programa.
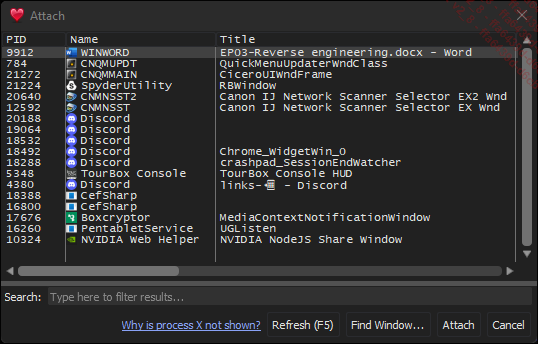
Para vincularse a un proceso en ejecución, hay que ir a File y seleccionar a continuación Attach (o [Ctrl] A). Aparece la lista de procesos en curso correspondientes a la arquitectura del depurador:
Basta con seleccionar el proceso en la lista haciendo doble clic sobre...