
BigML, machine learning para todos
Introducción
Ahora vamos a aprender a utilizar una herramienta de machine learning que no requiere el uso de ninguna línea de código y que, por tanto, puede:
-
ayudar a que se familiarice rápidamente con ciertas prácticas descritas en este libro, antes de intentar implementarlas en R,
-
permitir que un lector apurado o un manager adquiera un verdadero know how adicional a la simple descripción general de los capítulos referentes a las técnicas de este libro,
-
ayudar a identificar los modelos y los parámetros que parecen funcionar en un dataset, antes de introducirlos en sus códigos R. Así es como usamos esta herramienta, aplicándola a una pequeña parte de los datos de los que disponemos para tener una idea rápida (en media hora) de lo que los datos en cuestión pueden inferir sin transformación significativa.
BigML es una plataforma de machine learning que Francisco J. Martín creó en 2011 y que se basa en la nube. Permite llevar a cabo las principales etapas de exploración y transformación de datos, pero sobre todo permite crear rápidamente modelos y predicciones sin ningún conocimiento particular en data sciences. Con solo unos pocos clics, es posible construir y evaluar varios modelos de aprendizaje supervisados y no supervisados en sus datos. BigML tiene una «caja de herramientas» de modelos y funciones...
¿Para quién?
El número de perfiles disponibles y formados en herramientas de machine learning en la actualidad no es suficiente para cubrir la demanda de las empresas a nivel nacional e internacional. Para las empresas, estos perfiles de alto potencial están sujetos a una gran competencia y los recursos para montar un equipo de data science suelen ser difíciles de conseguir.
A priori, se podría pensar que una plataforma de machine learning es una herramienta necesariamente destinada a «iniciados», pero uno de los puntos fuertes de BigML es precisamente que se puede dirigir a un número mucho más grande de usuarios, al democratizar las prácticas de machine learning usando una herramienta fácil de dominar.
La herramienta limita el número de conceptos que se deben aprender y acelera el aprendizaje del usuario. Por lo tanto, la herramienta está dirigida a un público más amplio que solo a los data scientists científicos, como:
-
Los jefes de proyecto y business managers que deseen iniciar un proyecto de datos en su departamento (marketing, ventas, finanzas, investigación y desarrollo, etc.) de forma independiente, sin tener que recurrir al departamento de TI de la empresa,
-
desarrolladores, en particular a través de la API BigML, que permite una rápida implementación de modelos en las empresas,
-
estudiantes y profesores, que pueden...
Presentación del enfoque
No vamos a detallar todas las opciones disponibles en la herramienta BigML, sino que vamos a destacar la facilidad de implementación de un proceso estándar de machine learning mediante el uso de sus funciones básicas. Existen otras plataformas de machine learning que integran el uso de R, como ©Dataiku, que normalmente son más completas, pero también más difíciles de dominar. Hemos elegido presentar BigML por su rapidez de manejo y, obviamente, por su capacidad para documentar el proceso manual que haya utilizado (lo que le permitirá reproducirlo en su contexto R).
Con este ejercicio, vamos a ver cómo se pasa en BigML de una fuente de datos a una predicción. Este proceso incluye varios pasos:
-
seleccionar una fuente de datos,
-
crear un dataset (dataset),
-
dividirlo en conjuntos de entrenamiento y prueba (split),
-
crear un modelo,
-
evaluarlo.
Vamos a empezar sin más preámbulos. Después de crear su cuenta personal en el sitio https://bigml.com, inicie sesión y acceda a la plataforma.
Manipulación de las fuentes de datos
Desde el primer contacto con la herramienta, se encuentra en terreno conocido.
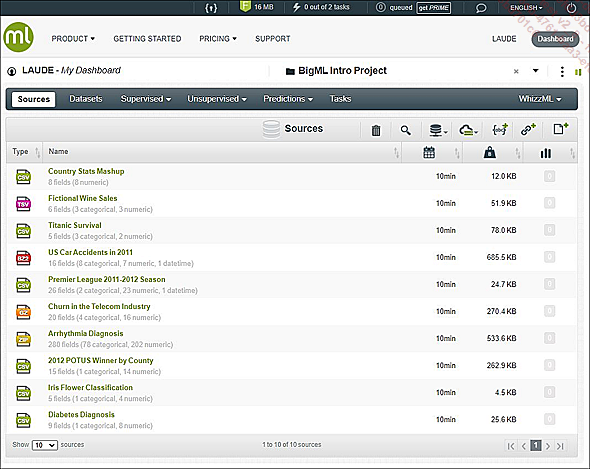
La pestaña Sources
La herramienta se presenta como un dashboard. La pestaña de inicio enumera las Sources de datos disponibles. Se ofrece un nuevo espacio de trabajo al usuario (llamado BigMLIntroProject) y permite acceder a varias fuentes de datos de demostración. Por lo tanto, un nuevo usuario puede explorar inmediatamente las funcionalidades disponibles. Para esta parte del libro, vamos a utilizar el archivo .csv «Diabetes Diagnosis» que contiene datos biológicos y fisiológicos de varias mujeres de la población indígena Pima (en los Estados Unidos). Estos datos forman parte de un estudio de diabetes y fueron publicados por el National Institute of Diabetes and Digestive and Kidney Diseases.
Para cada fuente, se indican los siguientes elementos:
-
Su extensión: BigML gestiona formatos de archivos de entrada .csv, .json, .txt, .xls (.numbers para ©Apple). También puede recibir formatos comprimidos, como archivos .zip, .gz o .bz2. Tener una herramienta capaz de procesar varios formatos en un solo lugar es muy cómodo.
-
Su nombre, el número de variables y su tipo.
-
Su fecha de importación o creación.
-
Su tamaño.
-
El número de datasets generados a partir de esta fuente.

Menú desplegable de una fuente de datos
A la derecha...
Creación de proyectos
BigML ofrece la posibilidad de tener una vista por proyecto para permitirle organizar y segmentar sus espacios de trabajo. Es posible iniciar un nuevo dashboard por cliente o por algún problema puntual de negocio. También le permite empezar de cero cuando pierde el control de la gestión de su espacio de trabajo.
Ruta de los proyectos
Nuestro consejo sobre nombres de archivos y versiones: para dominar sus procesos de machine learning, debe tener cuidado con la nomenclatura y las versiones de sus archivos (ya sean importados, generados o exportados). Rápidamente utilizará muchas fuentes a partir de las cuales se configurarán varios datasets. Seguirá la multiplicación del número de datasets y varias pruebas de modelos. Rápidamente, sus dashboards se llenarán y ya no podrá distinguir sus éxitos de sus fracasos. En estas condiciones, es difícil aspirar a obtener procesos reproducibles; téngalos contados y no dude en escribir una nota explicativa sobre su organización, sobre todo si trabaja con varias personas.
Manipulación de los datasets
La pestaña Datasets enumera todos los datasets generados a partir de sus fuentes, así como los diferentes tipos de modelos de machine learning llevados a cabo en los datasets.
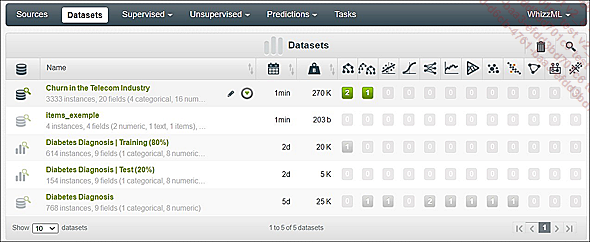
Lista de los datasets
Cuando se visualiza un dataset, los datos se presentan de forma descriptiva con una vista previa de las distribuciones y sus principales indicadores (mediana, desviación típica, coeficiente de curtosis, etc.). Para cada variable encontramos: su nombre, tipo, elementos totales, número de errores o datos ausentes y una representación visual de ella. El punto más importante en esta etapa del proceso es verificar que la herramienta haya identificado correctamente la variable que se ha de predecir (aquí, Diabetes). También hablamos de una variable «objetivo» (el pictograma que la simboliza es un punto de mira).
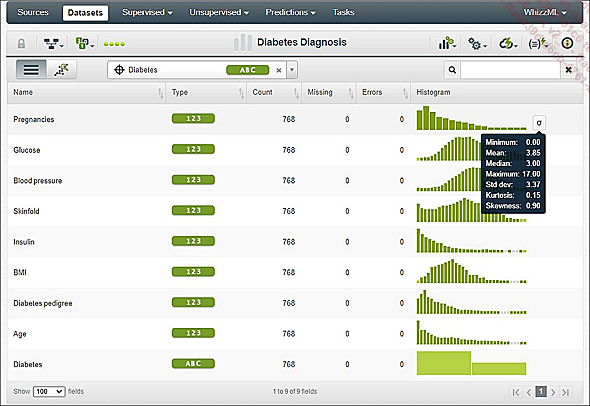
Visualización de un dataset
División del juego de datos
El primer pictograma (a la derecha del nombre de su dataset en forma de histograma) abre el menú de transformación y muestreo.
Haga clic en este enlace para acceder a la configuración del split de su dataset. En la pantalla anterior tenemos la ruta > 1-Clic sin parametrización (en la vista principal Dataset). Por defecto, el split está en las proporciones 80/20 y resulta ser aleatorio.

Ubicación de la función split
En esta parte de los parámetros del split, indicamos la distribución entre juegos de entrenamiento y de prueba. En otras palabras, construye su modelo con el 80 % de los datos de su dataset y se evalúa su rendimiento utilizando el 20 % restante.
Puede agregar un seed para fijar el comportamiento de su generador aleatorio o elegir una división lineal de su dataframe (generalmente se usa cuando está seguro de tener un juego ya «aleatorizado»).
Le animamos a que se plantee la cuestión de la nomenclatura elegida para los archivos que se generarán posteriormente (se puede referir a lo que decíamos unas líneas antes).
Ahora haga clic en el botón Create Training|Test: los dos nuevos datasets correspondientes a la división 80/20 aparecen en la pestaña Dataset de su dashboard.
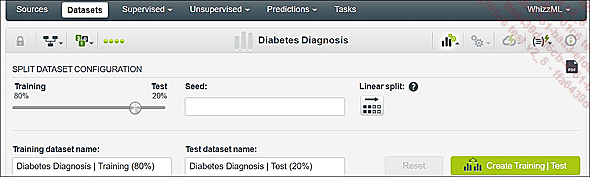
Elección de argumento del split
Volviendo a la vista general de los Datasets, podemos estudiar...
Creación de un modelo de machine learning
Nuestros datos se prestan bien al uso de un árbol de decisión. Tenga en cuenta que en BigML los árboles de decisión se denominan Modelos, y los bosques aleatorios, Conjuntos (que no se deben confundir con los modelos llamados «conjuntos», que se pueden corresponder con varios tipos de modelos). Los modelos recién creados se muestran en la pestaña correspondiente a su naturaleza. Como nuestro modelo forma parte de la categoría de modelos supervisados, se colocará en la pestaña Supervised del dashboard.
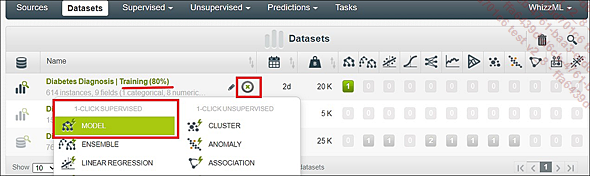
1-Click Árbol de decisión
BigML ahora ha generado un primer modelo deduciendo él mismo los parámetros (para demostrar la eficiencia de la herramienta, hemos optado por ir por el camino rápido).
1. Argumentos de los modelos
Por supuesto, puede configurar todos sus modelos al detalle. En este árbol de decisión, por ejemplo, podríamos trabajar el número de nodos, las instancias que se mantienen, el tipo de tirada, etc.
El botón que permite el acceso al espacio de configuración de su futuro modelo se encuentra dentro de la vista de su dataset (y no en la pantalla Datasets, que contiene todos los juegos de datos). Este botón Configurar (pictograma en forma de ruedas dentadas) está a la derecha del título.
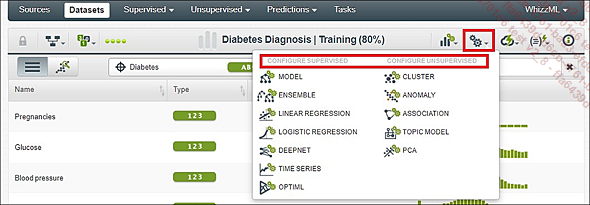
Menú de configuración de los modelos...
Evaluación del modelo
Ahora que hemos creado nuestro primer modelo, queremos evaluarlo en nuestro dataset de prueba. Para esto, BigML usará el modelo recién construido para usarlo como modelo de predicción en el 20 % de los datos de prueba.
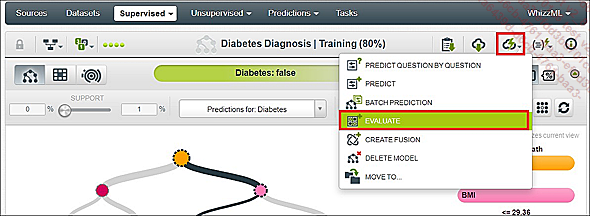
Función de evaluación del modelo
BigML le pide que marque el modelo que se ha de usar (columna izquierda) y el dataset para aplicarlo (columna derecha). En esta etapa, es útil cambiar el nombre de la evaluación para darle uno más personal y que nos permita distinguir nuestras diferentes pruebas.
Para iniciar la evaluación, haga clic en el botón Evaluate, en la parte inferior derecha.
Pantalla de configuración de la evaluación
Tras comparar los resultados de su predicción con la realidad del conjunto de pruebas, BigML nos proporciona una matriz de confusión y varios indicadores propios de la data science, como el índice de accuracy o la precisión.
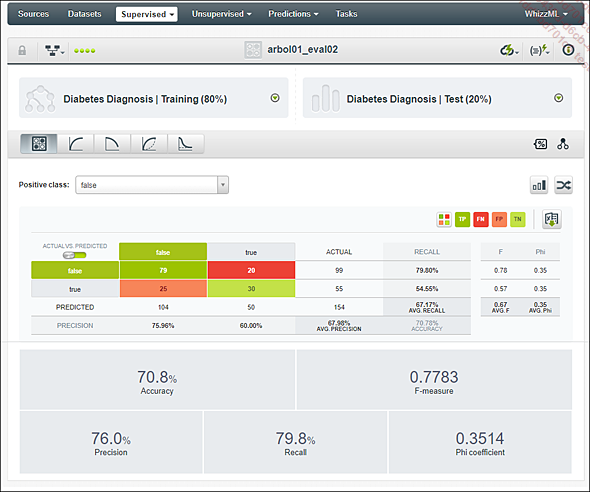
Evaluación del modelo
Tenga cuidado de elegir la clase determinada como «positiva» en la parte superior de la matriz de confusión. Dependiendo de si está solicitando evaluar (por lo tanto, predecir correctamente) el número de mujeres con diabetes (Positive class = TRUE) o al revés (Positive class = FALSE), el significado de «falso positivo» y «falso negativo» será diferente.
Compartir sus modelos
Con la opción Secret link, en la pestaña Privacy de su modelo, puede compartir sus modelos usando un enlace privado o una etiqueta iframe (útil para insertar sus resultados en un sitio web o blog). Los usuarios externos podrán consultar y manipular todo el dashboard relacionado con la vista de su modelo: las representaciones del modelo, la clasificación de las variables, los inputs para manipular las tasas de confianza, etc.). La opción NO CLONABLE permite hacer que sus modelos sean utilizables o no por otros usuarios.
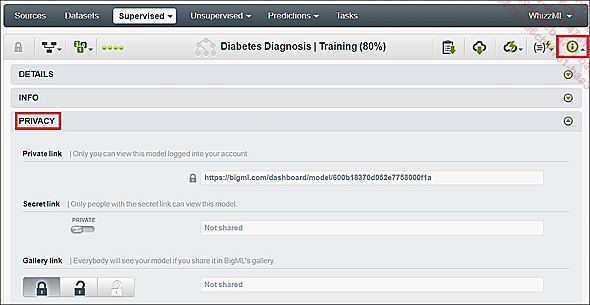
Compartir modelos
Realizar una primera predicción
Para completar este ejercicio, haremos una predicción usando nuestro modelo sobre nuevos datos, que aún no se han usado en nuestro proceso (en realidad, estos datos provienen de una extracción realizada previamente en el dataset original, que reservamos para simular que hacemos una predicción sobre nuevos datos).
Por lo tanto, ahora aplicamos nuestro árbol de decisión a los datos, simulando la realidad diaria de la explotación de dicho modelo (es decir, en instancias que no tienen valor en la columna Diabetes).
Pulse en Batch prediction para aplicar su modelo a un conjunto de instancias.
Ruta Batch prediction
¿No puede encontrar su dataset? ¿Está seguro de que importó la fuente y la convirtió en un dataframe en BigML?
Configuración de la predicción
Cuando los nombres de las variables del modelo y del juego de datos difieren, se debe tener cuidado de ingresar su correspondencia a través de la interfaz de BigML.
Para terminar, haga clic en el botón Predict.
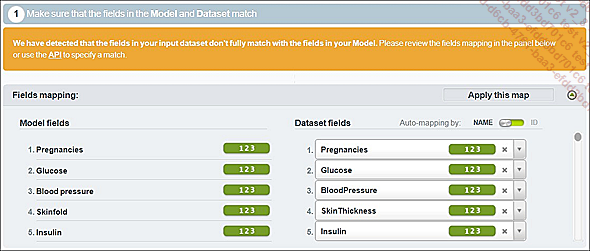
Correspondencia de las variables
BigML muestra ahora una vista previa del nuevo dataset. Se puede comprobar que predijo correctamente los nuevos valores de la variable Diabetes.
Descargue el archivo .csv en su ordenador usando el botón Download batch prediction.
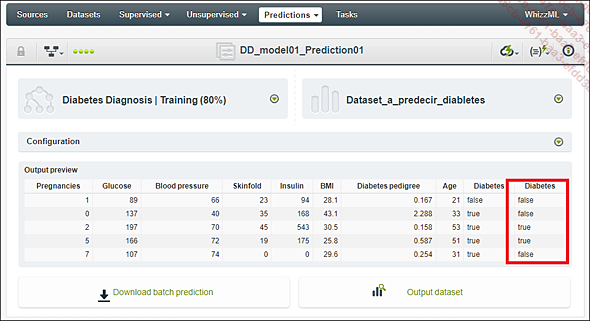
Archivo de salida
Ahora tenemos un modelo de predicción interactivo...
Utilización del modelo en R
Los modelos más interesantes para prototipar con BigML de cara a su uso en R son las redes neuronales. De hecho, con el paquete caret, hemos visto que solo se necesitan unas pocas líneas de código para crear y ejecutar un modelo R con datos en formato de tabla, similares a los que manipula BigML (consulte el capítulo Deep learning con TensorFlow y Keras, sección Puesta a punto de un modelo de referencia usando caret).
Por lo tanto, es inútil recuperar información sobre los modelos BigML más sencillos. En contraposición, ajustar los parámetros principales de una red neuronal es complicado. Es muy interesante realizar algunas pruebas en BigML con números de capas diferentes, números de neuronas diferentes, varias funciones de activación, varias tasas de aprendizaje (learning rate), etc.
La idea es sencilla:
-
realizar varias pruebas en BigML,
-
reproducir el workflow BigML que funcionó mejor en su entorno TensorFlow2/Keras como punto de partida para el resto de su estudio.
BigML lo ayuda en esto, lo que le brinda la posibilidad de exportar el script completo de las acciones que lo condujeron a un modelo determinado.
Aquí construimos una red neuronal en nuestros datos de «Diabetes Diagnosis» usando BigML. Esta red neuronal obtuvo una precisión o accuracy del 74 % (tardamos minutos en desarrollar esta red:...



